ARTIFICIAL INTELIGENCE AND CROWD BEHAVIOR
PENGANTAR KOMPUTASI MODERN
Dosen: I Made Wiryana S. Kom. MApp Sc
Disusun Oleh : Kelompok 3
KATA PENGANTAR
Segala puji dan syukur kami panjatkan kepada Tuhan Yang Maha Esa karena atas berkat rahmat dan karunia-Nya serta dorongan doa restu, dan dorongan dari berbagai pihak sehingga kelompok kami dapat menyelesaikan tugas penulisan buku ini dengan judul Artificial Intelligence Crowd Behavior. Kami penulis ingin mengucapkan banyak terimakasih kepada Bapak I Made Wiryana S. Kom. MApp Sc yang telah memberikan bimbingan maupun arahan kepada kelompok kami sehingga kami bisa memahami tugas yang telah diberikan oleh bapak dan mengerjakannya dengan baik.
Ucapan terimakasih juga kami ucapkan kepada teman-teman kelas 4IA08 yang telah turut membantu dalam memberikan informasi seputar pengerjaan tugas ini. Kami sebagai penulis menyadari bahwa buku yang kami susun ini masih jauh dari nilai sempurna, sehingga apabila ada penulisan nama maupun materi yang salah mohon dimaklumi. Dengan disusunnya buku ini, besar harapan kami dari tim penulis dapat membantu sekaligus memberikan informasi kepada pembaca agar dapat dimanfaatkan oleh pembaca di kemudian hari.
1 BAB I
PENDAHULUAN
Pada era modernisasi seperti dewasa ini, tidak asing lagi di telinga kita bila mendengar kata artificial intelligence atau dalam bahasa berarti kecerdasan buatan. Kecerdasan buatan merupakan kemajuan teknologi yang diciptakan manusia dimana mesin-mesin yang sebelumnya hanya bisa dioperasikan oleh operator guna menyelesaikan suatu permasalahan tertentu, kini memiliki kecerdasan yang hampir menyerupai manusia. Sehingga mesin-mesin ini mampu menganalisa suatu masalah dan mengambil langkah yang paling optimal untuk memberikan solusi dari permasalahan tersebut. Salah satu implementasi kecerdasan buatan yang paling umum kita temui ada pada video game.
Terdapat banyak genre video game. Dan diantara sekian banyak, yang selalu mendapat tempat di hati para pecintanya adalah game dengan genre free roaming role playing game, dimana bisa dengan bebas menjelajahi suatu lingkungan dan berinteraksi dengan banyak sekali non-player karakter di lingkungan tersebut yang dikenal dengan crowd (kerumunan). Agar kerumunan terlihat semirip mungkin dengan keadaan di lingkungan nyata, penggunaan crowd behaviour menjadi suatu hal yang essensial. Crowd behaviour juga dapat merujuk ke simulasi berdasarkan dinamika kelompok sosial, seringnya dalam perencanaan keselamatan publik. Dalam hal ini, fokusnya adalah perilaku orang banyak, dan bukan realisme visual, mengamati perilaku manusia dan interaksi diperhitungkan untuk meniru perilaku kolektif. Ini adalah metode guna menciptakan sinematografi virtual.
Entitas - juga disebut agen - diberikan kecerdasan buatan, yang memandu entitas didasarkan pada satu atau lebih fungsi, seperti penglihatan, pendengaran, emosi dasar, tingkat energi, tingkat agresivitas, dan sebagainya. Entitas diberi tujuan dan kemudian berinteraksi satu sama lain hanya sebagai anggota kerumunan nyata. Mereka sering diprogram untuk merespon perubahan di lingkungan mereka misalnya, mereka dapat mendaki bukit, melompati lubang, tangga skala, dll. Sistem ini jauh lebih realistis dari gerakan partikel, tapi sangat mahal untuk pemrograman dan pelaksanaannya. Tujuan dari penulisan ini adalah menyajikan cara untuk membuat model perilaku karakter otonom. Dengan menggunakan model titik-massa untuk agen dan dinamika Newtonian, gerak agen benar-benar ditentukan oleh gaya yang diterapkan melalui waktu.
Gaya tersebut terbagi dalam dua kategori:
• Gaya lingkungan eksternal. gaya gravitasi langsung menjadi pokok bahasan, tetapi bukan berarti menjadi satu-satunya gaya yang diperhitungkan dalam kategori ini. Agen biasanya menghormati secara pasif terhadap gaya-gaya yang ada disekitar mereka dan mereka diterapkan berdasarkan apapun yang menjadi keputusan agen.
• Keputusan internal agen berdasarkan kemampuan sang agen sendiri. Dalam permainan balap mobil misalnya, agen dibatasi oleh kecepatan maksimum dan percepatan. Dalam batas-batas ini, agen bebas untuk memutuskan gaya mana yang harus mereka gunakan untuk mencapai tujuannya. Demikian pula, satu-satunya yang bisa dilakukan pemain terhadap keputusan agen adalah memilih gaya mana yang digunakan pada waktu yang tepat
2 BAB II
2.1 KONSEP AI
2.1.1 Artificial Inteligence (Kecerdasan Buatan)
Artificial intelligence atau kecerdasan buatan, Didefinisikan sebagai kecerdasan entitas ilmiah. Sistem seperti ini umumnya dianggap komputer. Kecerdasan diciptakan dan dimasukkan ke dalam suatu mesin (komputer) agar dapat melakukan pekerjaan seperti yang dapat dilakukan manusia. Beberapa macam bidang yang menggunakan kecerdasan buatan antara lain sistem pakar, permainan komputer (games), logika fuzzy, jaringan syaraf tiruan dan robotika. Banyak hal yang kelihatannya sulit untuk kecerdasan manusia, tetapi untuk Informatika relatif tidak bermasalah. Seperti contoh: mentransformasikan persamaan, menyelesaikan persamaan integral, membuat permainan catur atau Backgammon. Di sisi lain, hal yang bagi manusia kelihatannya menuntut sedikit kecerdasan, sampai sekarang masih sulit untuk direalisasikan dalam Informatika. Seperti contoh: Pengenalan obyek atau muka, bermain sepak bola.
2.1.2 Definisi Kecerdasan Buatan
• H. A. Simon [1987] : “ Kecerdasan buatan (artificial intelligence) merupakan kawasan penelitian, aplikasi dan instruksi yang terkait dengan pemrograman komputer untuk melakukan sesuatu hal yang -dalam pandangan manusia adalah- cerdas”
• Rich and Knight [1991]: “Kecerdasan Buatan (AI) merupakan sebuah studi tentang bagaimana membuat komputer melakukan hal-hal yang pada saat ini dapat dilakukan lebih baik oleh manusia.”
• Encyclopedia Britannica: “Kecerdasan Buatan (AI) merupakan cabang dari ilmu komputer yang dalam merepresentasi pengetahuan lebih banyak menggunakan bentuk simbol-simbol daripada bilangan, dan memproses informasi berdasarkan metode heuristic atau dengan berdasarkan sejumlah aturan.”
Tujuan dari kecerdasan buatan menurut Winston dan Prendergast [1984]:
1. Membuat mesin menjadi lebih pintar (tujuan utama)
2. Memahami apa itu kecerdasan (tujuan ilmiah)
3. Membuat mesin lebih bermanfaat (tujuan entrepreneurial)
AI dapat dipandang dalam berbagai perspektif:
1. Dari perspektif Kecerdasan (Intelligence) AI adalah bagaimana membuat mesin yang “cerdas” dan dapat melakukan hal-hal yang sebelumnya dapat dilakukan oleh manusia.
2. Dari perspektif bisnis AI adalah sekelompok alat bantu (tools) yang berdaya guna, dan metodologi yang menggunakan tool-tool tersebut guna menyelesaikan masalah-masalah bisnis.
3. Dari perspektif pemrograman (Programming) AI termasuk didalamnya adalah studi tentang pemrograman simbolik, pemecahan masalah, proses pencarian (search).
4. Dari perspektif penelitian (research) Riset tentang AI dimulai pada awal tahun 1960-an, percobaan pertama adalah membuat program permainan (game) catur, membuktikan teori, dan general problem solving. AI adalah nama pada akar dari studi area.
Gambar 2.1 Task Domain of AI
2.1.3 Sejarah Kecerdasan Buatan
Pada awal abad 17, René Descartes mengemukakan bahwa tubuh hewan bukanlah apa-apa melainkan hanya mesin-mesin yang rumit. Blaise Pascal menciptakan mesin penghitung digital mekanis pertama pada 1642. Pada 19, Charles Babbage dan Ada Lovelace bekerja pada mesin penghitung mekanis yang dapat diprogram. Bertrand Russell dan Alfred North Whitehead menerbitkan Principia Mathematica, yang merombak logika formal. Warren McCulloch dan Walter Pitts menerbitkan "Kalkulus Logis Gagasan yang tetap ada dalam Aktivitas " pada 1943 yang meletakkan pondasi untuk jaringan syaraf. Tahun 1950-an adalah periode usaha aktif dalam AI. Program AI pertama yang bekerja ditulis pada 1951 untuk menjalankan mesin Ferranti Mark I di University of Manchester (UK): sebuah program permainan naskah yang ditulis oleh Christopher Strachey dan program permainan catur yang ditulis oleh Dietrich Prinz. John McCarthy membuat istilah "kecerdasan buatan " pada konferensi pertama yang disediakan untuk pokok persoalan ini, pada 1956.
Dia juga menemukan bahasa pemrograman Lisp. Alan Turing memperkenalkan "Turing test" sebagai sebuah cara untuk mengoperasionalkan test perilaku cerdas. Joseph Weizenbaum membangun ELIZA, sebuah chatterbot yang menerapkan psikoterapi Rogerian. Selama tahun 1960-an dan 1970-an, Joel Moses mendemonstrasikan kekuatan pertimbangan simbolis untuk mengintegrasikan masalah di dalam program Macsyma, program berbasis pengetahuan yang sukses pertama kali dalam bidang matematika.
Marvin Minsky dan Seymour Papert menerbitkan Perceptrons, yang mendemostrasikan batas jaringan syaraf sederhana dan Alain Colmerauer mengembangkan bahasa komputer Prolog. Ted Shortliffe mendemonstrasikan kekuatan sistem berbasis aturan untuk representasi pengetahuan dan inferensi dalam diagnosa dan terapi medis yang kadangkala disebut sebagai sistem pakar pertama. Hans Moravec mengembangkan kendaraan terkendali komputer pertama untuk mengatasi jalan berintang yang kusut secara mandiri.
Pada tahun 1980-an, jaringan syaraf digunakan secara meluas dengan algoritma perambatan balik, pertama kali diterangkan oleh Paul John Werbos pada 1974. Tahun 1990-an ditandai perolehan besar dalam berbagai bidang AI dan demonstrasi berbagai macam aplikasi. Lebih khusus Deep Blue, sebuah komputer permainan catur, mengalahkan Garry Kasparov dalam sebuah pertandingan 6 game yang terkenal pada tahun 1997. DARPA menyatakan bahwa biaya yang disimpan melalui penerapan metode AI untuk unit penjadwalan dalam Perang Teluk pertama telah mengganti seluruh investasi dalam penelitian AI sejak tahun 1950 pada pemerintah AS.
Tantangan Hebat DARPA, yang dimulai pada 2004 dan berlanjut hingga hari ini, adalah sebuah pacuan untuk hadiah $2 juta dimana kendaraan dikemudikan sendiri tanpa komunikasi dengan manusia, menggunakan GPS, komputer dan susunan sensor yang canggih, melintasi beberapa ratus mil daerah gurun yang menantang.
2.1.4 Domain Penelitian Dalam Kecerdasan Buatan
• Formal tasks (matematika, games)
• Mundane task (perception, robotics, natural language, common sense, reasoning)
• Expert tasks (financial analysis, medical diagnostics, engineering, scientific analysis, dll)
PERMAINAN (Game)
• Kebanyakan permainan dilakukan dengan menggunakan sekumpulan aturan.
• Dalam permainan digunakan apa yang disebut dengan pencarian ruang.
• Teknik untuk menentukan alternatif dalam menyimak problema ruang merupakan sesuatu yang rumit.
• Teknik tersebut disebut dengan HEURISTIC.
• Permainan merupakan bidang yang menarik dalam studi heuristic
NATURAL LANGUAGE
Suatu teknologi yang memberikan kemampuan kepada komputer untuk memahami bahasa manusia sehingga pengguna komputer dapat berkomunikasi dengan komputer dengan menggunakan bahasa sehari-hari.
ROBOTIK DAN SISTEM SENSOR
Sistem sensor, seperti sistem vision, sistem tactile, dan sistem pemrosesan sinyal jika dikombinasikan dengan AI, dapat dikategorikan kedalam suatu sistem yang luas yang disebut sistem robotik.
EXPERT SYSTEM
Sistem pakar (Expert System) adalah program penasehat berbasis computer yang mencoba meniru proses berpikir dan pengetahuan dari seorang pakar dalam menyelesaikan masalah-masalah spesifik.
Keuntungan sistem pakar:
1. Memungkinkan orang awam bisa mengerjakan pekerjaan para ahli.
2. Bisa melakukan proses secara berulang secara otomatis.
3. Menyimpan pengetahuan dan keahlian para pakar.
4. Mampu mengambil dan melestarikan keahlian para pakar (terutama yang termasuk keahlian langka).
5. Mampu beroperasi dalam lingkungan yang berbahaya.
6. Meliliki kemampuan untuk bekerja dangan informasi yang tidak lengkap dan mengandung ketidakpastian.
7. Tidak memerlukan biaya saat tidak digunakan, sedangkan pada pakar manusia memerlukan biaya sehari-hari.
8. Dapat digandakan (diperbanyak) desuai kebutuhan dengan waktu yang minimal dan sedikit biaya.
9. Dapat memecahkan masalah lebih cepat daripada kemampuan manusia dengan catatan
10. Menggunakan data yang sama.
11. Menghemat waktu dalam pengambilan keputusan.
12. Meningkatkan kualitas dalam produktivitas.
Kelemahan sistem pakar:
1. Biaya yang diperlukan untuk membuat dan memeliharanya sangat mahal.
2. Sulit dikembangkan. Hal ini tentu saja erat kaitannya dengan ketersediaannya pakar di bidangnya.
3. Sistem pakar tidak 100% bernilai benar.
|
Sistem Pakar
|
Kegunaan
|
|
MYCIN
|
Diagnosa penyakit
|
|
DENDRAL
|
Mengidentifikasi struktur melekular campuran kimia yang tak dikenal
|
|
XCON & XSEL
|
Membantu mengkonfirmasi sistem komputer besar
|
|
SOPHIE
|
Analisis sikrit elektronik
|
|
Prospector
|
Digunakan di dalam geologi untuk membantu mencari dan menemukan deposit
|
|
FOLIO
|
Membantu memberikan keputusan bagi seorang manajer dalam stok broker dalam investasi
|
|
DELTA
|
Pemelihataan lokomotif listrik diesel
|
2.1.5 Konsep dan Definisi Dalam Kecerdasan Buatan
TURING TEST – Metode Pengujian Kecerdasan
Turing Test merupakan sebuah metode pengujian kecerdasan yang dibuat oleh Alan Turing. Proses uji ini melibatkan seorang penanya (manusia) dan dua obyek yang ditanyai. Yang satu adalah seorang manusia dan satunya adalah sebuah mesin yang akan diuji. Penanya tidak bisa melihat langsung kepada obyek yg ditanyai. Penanya diminta untuk membedakan mana jawaban komputer dan mana jawaban manusia berdasarkan jawaban kedua obyek tersebut. Jika penanya tidak dapat membedakan mana jawaban mesin dan mana jawaban manusia maka Turing berpendapat bahwa mesin yang diuji tersebut dapat diasumsikan CERDAS.
PEMROSESAN SIMBOLIK
Komputer semula didisain untuk memproses bilangan atau angka-angka (pemrosesan numerik). Sementara manusia dalam berpikir dan menyelesaikan masalah lebih bersifat simbolik, tidak didasarkan kepada sejumlah rumus atau melakukan komputasi matematis. Sifat penting dari AI adalah bahwa AI merupakan bagian dari ilmukomputer yang melukan proses secara simbolik dan non-algoritmik dalam penyelesaian masalah
HEURISTIC
Istilah Heuristic diambil dari bahasa Yunani yang berarti menemukan. Heuristic merupakan suatu strategi untuk melakukan proses pencarian (search) ruang problema secara selektif, yang memandu proses pencarian yang kita lakukan disepanjang jalur yang memiliki kemung kinan sukses paling besar.
Metode pencarian heuristic:
1. Generate and Test (Pembangkit dan Pengujian)
2. Hill Climbing (Pendakian Bukit)
3. Best First Search (Pencarian Terbaik Pertama)
4. Simulated Annealing
PENARIKAN KESIMPULAN (INFERENCING) AI mencoba membuat mesin memiliki kemampuan berpikir atau mempertimbangkan (reasoning). Kemampuan berpikir (reasoning) termasuk didalamnya proses penarikan kesimpulan (inferencing) berdasarkan fakta-fakta dan aturan dengan menggunakan metode heuristik atau metode pencarian lainnya.
PENCOCOKAN POLA (PATTERN MATCHING) AI bekerja dengan metode pencocokan pola (pattern matching) yang berusaha untuk menjelaskan obyek, kejadian (events) atau proses, dalam hubungan logik atau komputasional.
Perbandingan Kecerdasan Buatan dengan Kecerdasan Alamiah
Keuntungan Kecerdasan Buatan dibanding kecerdasan alamiah:
1. Lebih permanen.
2. Memberikan kemudahan dalam duplikasi dan penyebaran.
3. Relatif lebih murah dari kecerdasan alamiah.
4. Konsisten dan teliti.
5. Dapat didokumentasi.
6. Dapat mengerjakan beberapa tugas dengan lebih cepat dan lebih baik dibanding manusia.
Keuntungan Kecerdasan Alamiah dibanding kecerdasan buatan:
1. Bersifat lebih kreatif.
2. Dapat melakukan proses pembelajaran secara langsung, sementara AI harus mendapatkan masukan berupa simbol dan representasi.
3. Fokus yang luas sebagai referensi untuk pengambilan keputusan sebaliknya AI menggunakan fokus yang sempit.
Komputer dapat digunakan untuk mengumpulkan informasi tentang obyek, kegiatan (events), proses dan dapat memproses sejumlah besar informasi dengan lebih efisien dari yang dapat dikerjakan manusia, tetapi disisi lain manusia dengan menggunakan insting dapat melakukan hal yang sulit untuk diprogram pada komputer, yaitu: manusia dapat mengenali (recognize) hubungan antara hal-hal tersebut, menilai kualitas dan menemukan pola yang menjelaskan hubungan tersebut.
2.1.6 Pendekatan pada Kecerdasan Buatan
1. Strong AI
Pendekatan ini ingin menuju ke pembuatan suatu mesin yang bisa benar benar berpikir dan memecahkan masalah. Mesin-mesin ini harus sadar akan dirinya dan kemampuannya, intelegensianya secara umum harus tidak bisa dibedakan dengan intelegensia seorang manusia. Optimisme berlebihan di sekitar tahun 1950 dan 1960 berkenaan dengan Strong AI telah memberi jalan bagi apresiasi tingkat kesulitan yang sangat tinggi untuk masalah tersebut. Pendekatan ini mempertahankan bahwa mesin yang di program dengan cukup akan mampu untuk memiliki keadaan mental kognitif (cognitive mental state).
2. Weak AI
Pendekatan ini berurusan dengan pembuatan Kecerdasan buatan di komputer yang tidak benar-benar bisa berpikir dan memecahkan masalah, namun bisa berprilaku seakan akan ia memiliki kecerdasan. Pendekatan ini menyatakan bahwa sebuah mesin yang di program dengan cukup akan dapat meniru pemikiran manusia.
3. Applied AI
Pendekatan ini berusaha menghasilkan suatu sistem cerdas yang secara komersial dapat digunakan, sebagai contoh sebuah sistem keamanan yang dapat mengenali wajah orang yang boleh memasuki gedung. Pendekatan ini sudah mengalami cukup banyak sukses.
4. Coginitive AI
Pendekatan ini memandang komputer sebagai alat untuk mengetes teori tentang bagaimana otak manusia bekerja. Sebagai contoh teori tentang bagaimana cara kita mengenali wajah, dan benda benda lainnya, atau bagaimana kita memecahkan masalah yang abstrak.
2.1.7 Aplikasi Kecerdasan Buatan
1. General Problem Solving
Bidang AI ini berhubungan dengan pemecahan masalah terhadap suatu situasi yang akan diselesaikan oleh komputer. Permasalahan yang diungkapkan dalam suatu cara yang sedemikian rupa sehingga komputer dapat mengerti. Semua deskripsi-deskripsi yang diinginkan juga diberikan kepada komputer. Biasanya permasalahaan tersebut dapat diselesaikan secara trial and error sampai solusi yang diinginkan didapatkan. Suatu program paket yang cukup populer di kompuer mikro untuk pemecahan masalah secara trial and error adalah EUREKA yang ditulis oleh Borland.
2. Speech Recognition
Bidang ini juga masih dikembangkan dan terus dilakukan penelitiannya. Kalau bidang ini berhasil dengan baik dan sempurna, alangkah hebatnya komputer. Kita dapat berkomunikasi dengan komputer hanya dengan bicara, kita bisa mengetik sebuah buku hanya dengan bicara, dan selanjutnya komputer yang akan menampilkan tulisan hasil pembicaraan kita. Akan tetapi bidang ini masih belum sempurna seperti yang diharapkan. Hal ini dikarenakan jenis suara manusia berbeda-beda.
Alat recognizer dapat ditambahkan pada komputer mikro sehingga dapat digunakan untuk speech recognition, diantaranya yaitu:
• Voice Recognition Module (VRM) buatan Interstate Electronic.
• SpeechLab buatan Heuristics Inc.
• Voice Entry Terminal (VET) buatan Scott Instruments.
• Cognivox buatan Voicetek.
• Voice Data Entry System (VDEC) buatan Interstate Electronic.
3. Visual Recognition
Bidang ini merupakan kemampuan suatu komputer yang dapat menangkap signal elektronik dari suatu kamera dan dapat memahami apa yang dilihat tersebut. Penerapan AI ini misalnya pada komputer yang dipasang di peluru kendali, sehingga peluru kendali dapat diprogram untuk selalu mengejar sasarannya yang tampak di kamera.
Pada era globalisasi saat ini, bidang Visual Recognition dapat kita jumpai pada komputer-komputer laptop terbaru. Mula-mula komputer dipasang alat untuk mendeteksi sidik jari (fingerprints password). Sekarang ini sudah banyak digunakan face detector, sehingga untuk mengakses sebuah laptop yang sudah dipasangi password dari gambar wajah orang pemiliknya, maka orang lain dengan wajah yang berbeda tidak akan dapat membuka laptop tersebut. Misalkan pada laptop LENOVO 3000 Y410 keluaran IBM.
4. Robotics Robot berasal dari kata Robota, dari bahasa Chekoslavia yang berarti tenaga kerja. kata ini digunakan oleh dramawan Karel Capek pada tahun 1920 pada sandiwara fiksinya, yaitu R.U.R (Rossum’s Universal Robots). Robot adalah suatu mesin yang dapat diarahkan untuk mengerjakan bermacam-macam tugas tanpa campur tangan lagi dari manusia. Secara ideal robot diharapkan dapat melihat, mendengar, menganalisa lingkungannya dan dapat melakukan tindakan-tindakan yang terprogram. Dewasa ini robot digunakan untuk maksud-maksud tertentu dan yang paling banyak adalah untuk keperluan industri. Diterapkannya robot untuk industri terutama untuk pekerjaan 3D yaitu Dirty, Dangerous, atau difficult (kotor, berbahaya dan pekerjaan yang sulit). Negara yang banyak menggunakan robot untuk industri adalah Jepang, Amerika Serikat dan Jerman Barat.
2.2 Crowd Simulation dan Crogai
Crowd Simulation adalah proses simulasi gerakan entitas atau karakter dalam jumlah yang banyak. Teknik ini biasa digunakan untuk grafis komputer 3D untuk perfilman di era sekarang. Sewaktu mensimulasi kerumunan atau keramaian, perilaku dan interaksi manusia yang telah diteliti akan diperhitungkan ke dalam algoritma untuk meniru perilaku kolektif untuk para karakter yang memiliki kecerdasan buatan. Ini adalah metode untuk menciptakan sinematografi virtual. Kebutuhan akan crowd simulation meningkat disaat dibutuhkannya sebuah scene atau adegan yang memerlukan banyak karakter yang dapat dijadikan animasi dengan mudah menggunakan sistem konvensional animasi 3D seperti pergerakan skeleton (rangka) dan bones (tulang) pada karakter 3D.
Crowd simulation atau mensimulasi keramaian memberikan keuntungan tersendiri dari segi biaya yang minim dan penghematan waktu untuk pemrograman animasi tiap karakter. Para animator biasanya akan membuat sekumpulan daftar motions atau pergerakan untuk karakter, baik untuk keseluruhan karakter ataupun hanya beberapa bagian tubuh karakter. Untuk mempermudah pemrosesan, animasi-animasi tersebut diolah menjadi morph. Perlu diketahui bahwa morph atau animasi morph target adalah metode komputasi animasi 3D yang menggunakan teknik skeletal animation atau animasi rangka. Biasanya teknik ini diterapkan dengan cara merubah atau memodifikasi posisi vertex pada rangka objek. Secara bergiliran, gerakan yang telah diolah menjadi morph tadi dapat dihasilkan secara prosedural. Contohnya menciptakan koreografi karakter menggunakan software tertentu.
Gambar 2.2 Face Morph Deformations Geometr
2.2.1 Crowd Behavior
Simulasi kerumunan juga dapat merujuk ke simulasi berdasarkan dinamika kelompok dan kerumunan psikologi manusia. Hal ini sering digunakan untuk perencanaan keselamatan public. Contohnya simulasi bagaimana orang-orang harus bertindak ketika terjadi gempa bumi dan lain-lain. Banyak penelitian telah difokuskan pada perilaku sosial kolektif orang di pertemuan sosial, majelis, protes, pemberontakan, konser, acara olahraga dan upacara keagamaan yang berhubungan dengan kerumunan. Hal ini menghasilkan wawasan tentang perilaku alami manusia pada berbagai jenis situasi stres yang akan memungkinkan terciptanya model yang lebih baik yang dapat digunakan untuk mengembangkan strategi pengendalian kerumunan.
Teknik pemodelan simulasi kerumunan atau keramaian dilakukan dari jaringan pendekatan untuk memahami aspek individualistis atau perilaku setiap agen atau personal. Misalnya Social Force Model menggambarkan kebutuhan bagi individu untuk menemukan keseimbangan antara interaksi fisik dan sosial. Sebuah pendekatan yang menggabungkan kedua aspek dan mampu beradaptasi tergantung pada situasi, akan lebih menggambarkan perilaku alami manusia. Dengan menggunakan model multi-agent, memahami perilaku kompleks akan menjadi tugas yang mudah dipahami. Dengan menggunakan software jenis ini, sistem dapat diuji dibawah kondisi ekstrem dan mensimulasikan kondisi jangka waktu yang lama dalam hitungan detik.
2.2.2 Gerakan Partikel
Karakter yang melekat pada partikel titik, yang kemudian animasi dengan mensimulasikan angin, gravitasi, atraksi, dan tabrakan. Metode partikel biasanya murah untuk melaksanakan, dan dapat dilakukan di sebagian besar paket perangkat lunak 3D. Namun, metode ini sangat tidak realistis karena sulit untuk mengarahkan entitas individu bila diperlukan. Juga, gerak umumnya terbatas pada permukaan datar.
Entitas (juga disebut agen) diberikan kecerdasan buatan, yang memandu entitas didasarkan pada satu atau lebih fungsi, seperti penglihatan, pendengaran, emosi dasar, tingkat energi, tingkat agresivitas, dll Entitas diberi tujuan dan kemudian berinteraksi satu sama lain hanya sebagai anggota kerumunan nyata akan. Mereka sering diprogram untuk merespon perubahan di lingkungan mereka; misalnya, mereka dapat mendaki bukit, melompati lubang, tangga skala, dll Sistem ini jauh lebih realistis dari gerakan partikel, tapi sangat mahal untuk program dan melaksanakan.
Contoh yang paling terkenal dari simulasi AI dapat dilihat di New Line Cinema The Lord of the Rings film, di mana AI ribuan karakter tentara bertempur satu sama lain. Simulasi kerumunan ini dilakukan dengan menggunakan software besar Weta Digital. Kecerdasan buatan (AI) adalah kecerdasan yang ditunjukkan oleh mesin atau perangkat lunak. Ini juga merupakan bidang akademik studi. Peneliti AI utama dan buku teks mendefinisikan lapangan sebagai "studi dan desain agen cerdas", di mana suatu agen cerdas adalah sistem yang memandang lingkungannya dan mengambil tindakan yang memaksimalkan peluang keberhasilannya. John McCarthy, yang menciptakan istilah pada tahun 1955, mendefinisikan sebagai "ilmu dan teknik pembuatan mesin yang cerdas".
Penelitian AI sangat teknis dan khusus, dan sangat dibagi menjadi subbidang yang sering gagal untuk berkomunikasi satu sama lain Beberapa divisi ini karena faktor sosial dan budaya:. Subbidang telah tumbuh di sekitar lembaga tertentu dan pekerjaan individu peneliti. Penelitian AI juga dibagi oleh beberapa masalah teknis. Beberapa subbidang fokus pada solusi dari masalah-masalah tertentu. Lain fokus pada salah satu dari beberapa pendekatan yang mungkin atau pada penggunaan alat tertentu atau terhadap pemenuhan aplikasi tertentu.
Masalah sentral (atau tujuan) penelitian AI meliputi penalaran, pengetahuan, perencanaan, pembelajaran, pengolahan bahasa alami (komunikasi), persepsi dan kemampuan untuk bergerak dan memanipulasi objek. kecerdasan umum masih antara tujuan-tujuan jangka panjang dari lapangan tersebut. Saat ini pendekatan yang populer meliputi metode statistik, kecerdasan komputasi dan simbolis AI tradisional.. Ada sejumlah besar alat yang digunakan dalam AI, termasuk versi pencarian dan optimasi matematika, logika, metode berdasarkan probabilitas dan ekonomi, dan banyak lainnya. Bidang AI adalah interdisipliner, di mana sejumlah ilmu dan profesi berkumpul, termasuk ilmu komputer, psikologi, linguistik, filsafat dan ilmu saraf, serta bidang khusus lainnya seperti psikologi buatan.
Bidang ini didirikan pada klaim bahwa properti pusat manusia, intelijen-yang cita rasa dari Homo sapiens-"bisa begitu tepat dijelaskan bahwa mesin dapat dibuat untuk mensimulasikan itu." Hal ini menimbulkan persoalan filosofis tentang sifat pikiran dan etika menciptakan makhluk buatan diberkahi dengan kecerdasan manusia-seperti, masalah yang telah ditangani oleh mitos, fiksi dan filsafat sejak jaman dahulu. kecerdasan buatan telah menjadi subjek optimisme yang luar biasa tetapi juga telah menderita menakjubkan kemunduran.
Hari ini telah menjadi bagian penting dari industri teknologi, menyediakan angkat berat bagi banyak masalah yang paling menantang dalam ilmu komputer. Artificial Intelegence Crowd Behaviour, percobaan untuk memperkenalkan beberapa kecerdasan buatan dalam skenario dimana terdapat kerumunan besar dari karakter-karakter dan kerumunan ini menjalankan suatu perilaku tertentu. Selain itu, agen dapat memancarkan spora di lingkungan, dan mereka pada gilirannya digunakan dalam algoritma genetika untuk berevolusi agen. Banyak perilaku yang menarik diamati, ledakan populasi dan kepunahan yang umum. Sebuah framework juga tersedia untuk menggunakan algoritma mesin pembelajaran bukan saat eksplisit AI, seperti jaringan saraf, tapi tidak hanya.
2.2.4 Crowd Rendering
Kerumunan orang dapat menjadi tontonan yang mengesankan dan sering digunakan secara efektif oleh film untuk menyampaikan kesempatan dan keagungan. Meski berpose serangkaian tantangan yang unik, membawa orang banyak ke domain real-time dapat meningkatkan realisme yang dirasakan dari lingkungan virtual. Namun, upaya saat ini umumnya jatuh pendek dari peningkatan user-harapan dengan rasa perendaman cepat terhalau ketika anggota berhenti tampil realistis dan berbeda.
Dengan demikian, ada 3 tujuan dalam mendefinisikan sistem rendering kerumunan :
• Kemampuan untuk mengelola karakter dalam jumlah besar
• Grafis berkualitas tinggi, penampilan menarik dan animasi
• Individualis
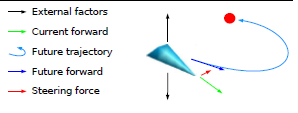
Crogai adalah sebuah percobaan untuk memperkenalkan kecerdasan buatan ke dalam skenario crowd behavior. Ini adalah proyek eksperimental. adalah memungkinkan untuk merancang simulasi dan percobaan perbedaan kecerdasan buatan ke dalam lingkungan 3D yang lengkap seperti engine fisik skala kecil, terrain, collision handling dan lain-lain. Tujuan utamanya adalah untuk membentuk lingkungan environmental yang lebih baik, yang dapat memperbolehkan kecerdasan buatan untuk berperan aktif.
Dalam hal ini, Crogai terinspirasi oleh proyek OpenSteer dan menggunakan kembali steering behavior yang disajikan oleh Craig Reynolds selama konvensi game developer pada tahun 1999. Crogai bekerja di kedua grafis dan modus batch berkat arsitektur simulator-dasar, yang memungkinkan rasio waktu waktu / simulasi nyata dari setiap nilai sewenang-wenang, tergantung pada kapasitas mesin. Beberapa percobaan modeling crowd simulation menggunakan Crogai dilakukan untuk mempelajari perilaku agent atau karakter yang ada pada sebuah lingkungan.
Karakter atau agent didesain sederhana dan hanya berbentuk kotak kecil dan dibuat berbeda-beda berdasarkan warna. Disediakan juga satu terrain atau dataran yang berfungsi sebagai lingkungan para agent berada.
Gambar 2.3 Simulasi evolusi spesies agent
Berdasarkan gambar diatas, agen spesies atau karakter dapat berevolusi. Agen dapat berburu, menyebarkan spora dan bereproduksi. Terlihat pada gambar bahwa awan spora berasal dari spesies yang berbeda, dan patch dari tanah dimana rumput dimakan. Hal ini berarti bahwa karakter atau agen yang memiliki kecerdasan buatan dapat bertindak dan berkembangbiak sesuai pada lingkungannya.
Gambar 2.4 Simulasi evolusi spesies agent
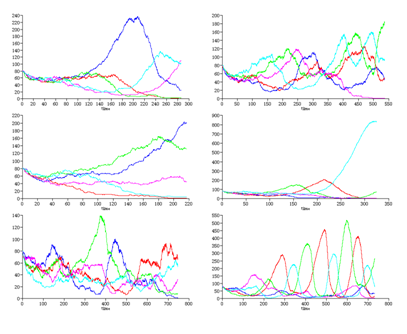
Pada skema yang sama, terlihat 3 agent karakter berwarna biru yang merumput pada dasar tanah, tapi karakter agent predator berwarna cyan dan magenta datang mendekat. Lalu lihat pada latar gambar, setiap spesies agent dapat merumput dan berburu dengan sendirinya pada saat diawal simulasi berjalan. Seiring waktu berjalan, mereka dapat berevolusi. Beberapa hasil dari evolusi populasi pada suatu waktu. Terlihat jumlah masing-masing spesies pada grafik di bawah ini. Jumlah spesies menurun hingga spesies mereka punah oleh predator yang ada pada lingkungan terrain pada simulasi.
Gambar 2.5 Grafik populasi agent pada suatu terrain
Pada percobaan lain, agent yang memiliki kecerdasan buatan dengan crowd behavior akan cenderung membuat kelompok. Terlihat pada gambar percobaan dibawah ini bahwa karakter agent yang lain memutuskan untuk membuat kelompok dan agent lain mengikuti kelompok tersebut. Terlihat apabila salah satu agent pergi meninggalkan area atau memutuskan untuk melakukan sesuatu, maka agent lainnya yang tergabung dalam kelompok tersebut akan mengikutinya.
Gambar 2.6 Agent AI membentuk kelompok
Pada eksperimen yang lain, dilakukan percobaan untuk mengamati perilaku antar agent pada suatu terrain dan mereka saling bertarung untuk bertahan hidup demi kelompoknya. Agent yang berkelompok pada percobaan sebelumnya diprogram untuk tetap pada kelompoknya. Mereka juga diprogram untuk menyerang spesies lain dan bertahan hidup dengan menghindari kemungkinan dimakan oleh spesies lain. Agent mendapatkan energi jika memakan sesuatu dan menghabiskan energinya untuk bergerak. Sayangnya, sistem ini masih belum cukup stabil untuk diterapkan pada game atau film. Untuk game dan film lebih cocok menggunakan crowd simulation konvensional.
2.3 Simulasi
Simulasi adalah suatu cara untuk menduplikasi atau menggambarkan ciri, tampilan, dan karakteristik dari suatu sistem nyata. Ide awal dari simulasi adalah untuk meniru situasi dunia nyata secara matematis, kemudian mempelajari sifat dan karakter operasionalnya, dan akhirnya membuat kesimpulan dan membuat keputusan berdasar hasil dari simulasi. Dengan cara ini, sistem di dunia nyata tidak disentuh atau dirubah sampai keuntungan dan kerugian dari apa yang menjadi kebijakan utama suatu keputusan di uji cobakan dalam sistem model.
2.3.1 Metode Simulasi
Metode simulasi merupakan proses perancangan model dari suatu sistem nyata (riil) dan pelaksanaan eksperimen-eksperimen dengan model ini untuk tujuan memahami tingkah laku sistem atau untuk menyusun strategi (dalam suatu batas atau limit yang ditentukan oleh sebuah satu atau beberapa kriteria) sehubungan dengan operasi sistem tersebut. Metode simulasi dapat menjelaskan tingkah laku sebuah sistem dalam beberapa waktu dengan mengobservasi tingkah laku dari sebuah model matematika yang dibuat sesuai dengan karakter sistem yang asli sehingga seorang analis bisa mengambil kesimpulan tentang tingkah laku dari sistem dunia nyata.
2.3.2 Klasifikasi simulasi
1. Model Simulasi Statik vs. Dinamik Model static merepresentasi sistem pada waktu tertentu. Waktu tidak berperan di sini. Contoh dari model ini yaitu Monte Carlo. Model dinamik merepresentasikan sistem dalam perubahannya terhadap waktu. Contoh dari model dinamik yaitu sistem conveyor di pabrik.
2.Model Simulasi Deterministik vs. Stokastik Model deterministic tidak memiliki komponen probabilistik (random). Model stokastik memiliki komponen input random, dan menghasilkan output yang random pula.
3.Model Simulasi Kontinu vs. Diskrit Model kontinu statusnya berubah secara kontinu terhadap waktu. Contohnya gerakan pesawat terbang. Sedangkan model diskrit, statusnya berubah secara instan pada titik-titik waktu yang terpisah. Sebagai contoh yaitu jumlah customer di bank.
2.4 BAHASA C++
Berbicara mengenai C++ biasanya tidak lepas dari C, sebagai bahasa pendahulunya. Pencipta C adalah Brian W. Kerninghan dan Dennis M. Ritchie pada sekitar tahun 1972, dan sekitar satu dekade setelahnya diciptakanlah C++, oleh Bjarne Stroustrup dari Laboratorium Bell, AT&T, pada tahun 1983. C++ cukup kompatibel dengan bahasa pendahulunya C. Pada mulanya C++ disebut “ a better C “. Nama C++ sendiri diberikan oleh Rick Mascitti pada tahun 1983, yang berasal dari operator increment pada bahasa C. Keistimewaan yang sangat berari dari C++ ini adalah karena bahasa ini mendukung Pemrograman Berorientasi Objek ( OOP / Object Oriented Programming).
2.4.2 Sejarah C++
Tahun 1978, Brian W. Kerninghan & Dennis M. Ritchie dari AT & T Laboratories mengembangkan bahasa B menjadi bahasa C. Bahasa B yang diciptakan oleh Ken Thompson sebenarnya merupakan pengembangan dari bahasa BCPL ( Basic Combined Programming Language ) yang diciptakan oleh Martin Richard.Sejak tahun 1980, bahasa C banyak digunakan pemrogram di Eropa yang sebelumnya menggunakan bahasa B dan BCPL. Dalam perkembangannya, bahasa C menjadi bahasa paling populer diantara bahasa lainnya, seperti PASCAL, BASIC, FORTRAN.
Gambar 2.8 Brian W Kerningham
Tahun 1989, dunia pemrograman C mengalami peristiwa penting dengan dikeluarkannya standar bahasa C oleh American National Standards Institute (ANSI). Bahasa C yang diciptakan Kerninghan & Ritchie kemudian dikenal dengan nama ANSI C.Mulai awal tahun 1980, Bjarne Stroustrup dari AT & T Bell Laboratories mulai mengembangkan bahasa C. Pada tahun 1985, lahirlah secara resmi bahasa baru hasil pengembangan C yang dikenal dengan nama C++. Symbol ++ merupakan operator C untuk operasi penaikan, muncul untuk menunjukkan bahwa bahasa baru ini merupakan versi yang lebih canggih dari C.
Sebenarnya bahasa C++ mengalami dua tahap evolusi. C++ yang pertama, dirilis oleh AT&T Laboratories, dinamakan cfront. C++ versi kuno ini hanya berupa kompiler yang menterjemahkan C++ menjadi bahasa C.Borland International merilis compiler Borland C++ dan Turbo C++. Kedua compiler ini sama-sama dapat digunakan untuk mengkompilasi kode C++. Bedanya, Borland C++ selain dapat digunakan dibawah lingkungan DOS, juga dapat digunakan untuk pemrograman Windows.Pada evolusi selanjutnya, Borland International Inc. mengembangkan kompiler C++ menjadi sebuah kompiler yang mampu mengubah C++ langsung menjadi bahasa mesin (assembly). Sejak evolusi ini, mulai tahun 1990 C++ menjadi bahasa berorientasi obyek yang digunakan oleh sebagian besar pemrogram professional.
Selain Borland International, terdapat beberapa perusahaan lain yang juga merilis compiler C++, seperti Topspeed C++ dan Zortech C++.
2.4.3 Struktur Pemrograman C++
Gambar 2.9 Struktur Program
Penjelasan dari program di atas sebagai berikut:
// program pertamaku
Merupakan sebuah baris komentar. Semua baris, yang ditandai dengan dua buah tanda slash (//), akan dianggap sebagai baris komentar dan tidak akan berpengaruh pada hasil. Biasanya, baris komentar dipakai oleh programmer untuk memberikan penjelasan tentang program. Baris komentar dalam C++, selain ditandai dengan (//) juga dapat ditandai dengan (/*….*/)
Perbedaan mendasar dari keduanya adalah : // baris komentar /* blok komentar */
#include “iostream”
Pernyataan yang diawali dengan tanda (#) merupakan pernyataan untuk menyertakan preprocessor. Pernyataan ini bukan untuk dieksekusi. #include “iostream” berarti memerintahkan kompiler untuk menyertakan file header iostream.h. Dalam file header ini, terdapat beberapa fungsi standar yang dipakai dalam proses input dan output. Seperti misalnya perintah cout yang dipakai dalam program utama.
int main ()
Baris ini menandai dimulainya kompiler akan mengeksekusi program. Atau dengan kata lain, pernyataan main sebagai penanda program utama. Adalah suatu keharusan, dimana sebuah program yang ditulis dalam bahasa C++ memiliki sebuah main. Main diikuti oleh sebuah tanda kurung () karena main merupakan sebuah fungsi. Dalam bahasa C++ sebuah fungsi harus diikuti dengan tanda (), yang nantinya dapat berisi argumen. Dan sintak formalnya, sebuah fungsi dimulai dengan tanda {}, seperti dalam contoh program.
cout << “Selamat Belajar C++”;
Perintah ini merupakan hal yang akan dieksekusi oleh compiler dan merupakan perintah yang akan dikerjakan. cout termasuk dalam file iostream. cout merupakan perintah untuk menampilkan ke layer. Perlu diingat, bahwa setiap pernyataan dalam C++ harus diakhiri dengan tanda semicolon (;) untuk memisahkan antara pernyataan satu dengan pernyataan lainnya.
system(“pause”);
Pernyataan ini berfungsi untuk menghentikan sementara program yang berjalan.
return 0;
Pernyataan return akan menyebabkan fungsi main() menghentikan program dan mengembalikan nilai kepada main. Dalam hal ini, yang dikembalikan adalah nilai 0.
2.4.4 Fungsi-Fungsi Penampil dan Pemasukan Data
Untuk keperluan penampilan data/informasi, Turbo C menyediakan sejumlah fungsi, diantaranya adalah PRINTF ( ), PUTS ( ) dan PUTCHAR ( ).
PRINTF ( )
Merupakan fungsi yang paling umum digunakan dalam menampilkan data. Berbagai jenis data dapat ditampilkan ke layar dengan fungsi ini.
Bentuk penulisan : printf(“string kontrol”, argumen1, argumen2, …);
- String kontrol dapat berupa keterangan yang akan ditampilkan pada layar beserta penentu format seperti %d, %f. Penentu format dipakai untuk memberi tahu kompiler mengenai jenis data yang akan ditampilkan
- Argumen adalah data yang akan ditampilkan ke layar. Argumen ini dapatr berupa variabel, konstanta atau ungkapan
PUTS ( )
Fungsi ini digunakan khusus untuk menampilkan data string ke layar. Sifat fungsi ini, string yang ditampilkan secara otomatis akan diakhiri dengan \n (pindah baris).
Dibandingkan dengan printf(), perintah ini mempunyai kode mesin yang lebih pendek.
PUTCHAR ( )
Digunakan khusus untuk menampilkan sebuah karakter ke layar. Penampilan karakter tidak diakhiri dengan perpindahan baris, misalnya : putchar(‘A’); sama dengan printf(“%c”, A); Data dapat dimasukkan lewat keyboard saat eksekusi berlangsung.
Fungsi yang digunakan untuk memasukkan data diantaranya adalah : scanf ( ), getch ( ), dan getche ( ) .
SCANF ( )
Merupakan fungsi yang dapat digunakan untuk memasukkan berbagai jenis data. Bentuk scanf ( ) sesungguhnya menyerupai fungsi printf ( ) yang melibatkan penentu format. Bentuk penulisan : scanf(“string kontrol”, daftar argumen); Hal-hal yang perlu diperhatikan dalam pemakaian scanf yaitu :
1. scanf memberi pergantian baris secara otomatis, artinya Anda tidak perlu memberi \n untuk berpindah ke baris berikutnya.
2. scanf memakai penentu format, tetapi tidak memerlukan penentu lebar field. Contoh yang salah : scanf(“10.2f”,&gaji);
3. Variabel yang dipakai di dalam scanf harus didahului dengan operator alamat (&).
MEMASUKKAN BEBERAPA DATA SECARA BERSAMA-SAMA Data dapat dimasukkan secara bersama-sama dalam satu baris. Setiap data dipisahkan oleh sebuah karakter. Karakter-karakter yang dapat bertindak sebagai pemisah data adalah : - Koma (‘) - Garis hubung (-) - Titik dua (:) - Spasi
GETCH ( ) dan GETCHE ( )
Dipakai untuk membaca sebuah karakter dengan sifat karakter yang dimasukkan tidak perlu diakhiri dengan enter. Fungsi getch() merupakan singkatan dari get character artinya baca karakter tetapi isian data yang dimasukkan tidak akan ditampilkan di layar. Nama fungsi getche() sebenarnya adalah singkatan dari get character and echo, artinya baca karakter lalu tampilkan di layar. Jadi setelah mengetikkan sebuah huruf, huruf tersebut akan ditampilkan di layar tanpa menekan enter.
Catatan :
- Program yang menggunakan printf(), putchar(), scanf() dan puts() mengandung baris yang berisi #include
- Program yang melibatkan getche() atau getch() mengandung baris yang berisi #include
3 BAB III
3.1 VEKTOR 2D DAN MEDAN SKALAR PLOTTER
3.1.1 Definisi Vektor
Dalam kalkulus vektor , medan vektor adalah tugas dari vektor untuk setiap titik dalam subset dari ruang Euclidean . Sebuah medan vektor di pesawat, misalnya, dapat dilihat sebagai kumpulan panah dengan kekuatan tertentu dan arah masing-masing melekat pada suatu titik di dalam pesawat. Bidang vektor yang sering digunakan untuk model, contohnya, kecepatan dan arah dari cairan bergerak di seluruh ruang, atau kekuatan dan arah dari beberapa kekuatan , seperti magnet atau gravitasi kekuatan, karena perubahan dari titik ke titik. Unsur-unsur diferensial dan kalkulus integral meluas ke bidang vektor dengan cara alami. Ketika medan vektor merepresentasikan kekuatan, yang terpisahkan garis dari medan vektor merupakan kerja yang dilakukan oleh kekuatan bergerak sepanjang jalan, dan di bawah ini interpretasi konservasi energi dipamerkan sebagai kasus khusus dari teorema dasar kalkulus . Bidang vektor dapat berguna dianggap sebagai mewakili kecepatan aliran bergerak di ruang angkasa, dan intuisi fisik ini menyebabkan gagasan seperti perbedaan (yang merupakan laju perubahan volume aliran) dan keriting (yang merupakan rotasi aliran). Dalam koordinat, medan vektor pada domain dalam n-dimensi ruang Euclides dapat direpresentasikan sebagai fungsi vektor bernilai yang mengaitkan sebuah n-tupel bilangan real untuk setiap titik dari domain. Ini representasi dari medan vektor tergantung pada sistem koordinat, dan ada yang terdefinisi dengan hukum transformasi dalam melewati dari satu sistem koordinat yang lain. Bidang vektor sering dibahas pada himpunan bagian terbuka dari ruang Euclidean, tetapi juga masuk akal pada himpunan bagian lain seperti permukaan , di mana mereka mengasosiasikan panah bersinggungan dengan permukaan pada setiap titik (a vektor singgung ). Secara umum, bidang vektor didefinisikan pada manifold terdiferensialkan , yang adalah ruang yang terlihat seperti ruang Euclidean pada skala kecil, tetapi mungkin memiliki struktur yang lebih rumit pada skala yang lebih besar. Dalam pengaturan ini, medan vektor memberikan vektor singgung pada setiap titik yang bermacam-macam (yaitu, bagian dari bundel singgung ke manifold). Bidang vektor adalah salah satu jenis bidang tensor .
Contoh Medan aliran di sekitar sebuah pesawat merupakan medan vektor di R 3, di sini divisualisasikan dengan gelembung yang mengikuti arus yang menunjukkan pusaran ujung sayap .
• Sebuah medan vektor untuk pergerakan udara di Bumi akan mengasosiasikan untuk setiap titik di permukaan bumi vektor dengan kecepatan dan arah angin untuk saat itu. Hal ini dapat ditarik dengan menggunakan panah untuk mewakili angin; panjang ( magnitude ) dari panah akan menjadi indikasi kecepatan angin. A "tinggi" pada biasa tekanan barometrik peta kemudian akan bertindak sebagai sumber (panah menunjuk jauh), dan "rendah" akan menjadi sink (panah menunjuk ke arah), karena udara cenderung bergerak dari daerah bertekanan tinggi ke daerah tekanan rendah .
• Velocity bidang yang bergerak cairan . Dalam kasus ini, kecepatan vektor berhubungan dengan setiap titik dalam cairan.
• Arus, Streaklines dan Pathlines 3 jenis garis yang dapat dibuat dari bidang vektor. Mereka adalah: streaklines - sebagaimana terungkap dalam terowongan angin menggunakan asap. -arus (atau fieldlines) - sebagai garis yang menggambarkan bidang sesaat pada waktu tertentu. pathlines - menunjukkan jalan yang partikel tertentu (nol massa) akan mengikuti.
• Medan magnet . The fieldlines dapat terungkap dengan menggunakan kecil besi pengajuan.
• Persamaan Maxwell memungkinkan kita untuk menggunakan satu set kondisi awal untuk menyimpulkan, untuk setiap titik dalam ruang Euclides , besaran dan arah untuk gaya yang dialami oleh tes partikel bermuatan pada saat itu; medan vektor yang dihasilkan adalah medan elektromagnetik .
• Sebuah medan gravitasi yang dihasilkan oleh benda masif juga merupakan medan vektor. Sebagai contoh, vektor medan gravitasi untuk tubuh bola simetris akan semua titik menuju pusat bola dengan besarnya vektor mengurangi jarak sebagai radial dari tubuh meningkat.
3.1.2 Definisi Skalar
Dalam matematika dan fisika , medan skalar mengaitkan skalar nilai setiap titik dalam ruang. Skalar dapat berupa nomor matematika , atau kuantitas fisik . Bidang skalar dituntut untuk koordinat-independen, yang berarti bahwa setiap dua pengamat menggunakan satuan yang sama akan setuju pada nilai medan skalar pada titik yang sama dalam ruang (atau ruang-waktu). Contoh yang digunakan dalam fisika meliputi suhu distribusi di seluruh ruang, tekanan distribusi dalam cairan, dan spin-nol bidang kuantum, seperti medan Higgs . Bidang ini merupakan subyek dari teori medan skalar .
Secara matematis, medan skalar pada daerah U adalah nyata atau fungsi kompleks bernilai atau distribusi pada U. Wilayah U mungkin satu set dalam beberapa ruang Euclidean , ruang Minkowski , atau lebih umum subset dari bermacam-macam , dan itu adalah khas dalam matematika untuk memaksakan kondisi lebih lanjut di lapangan, sehingga itu terus menerus atau sering terus terdiferensialkan beberapa order. Sebuah medan skalar adalah bidang tensor orde nol, dan istilah "medan skalar" dapat digunakan untuk membedakan fungsi semacam ini dengan medan yang lebih umum tensor, kepadatan , atau bentuk diferensial .
Vektor 2D dan Medan Skalar Plotter dapat menampilkan :
• Baris Konvolusi Integral (LIC) pada data.
• Lengkung skala panah mengikuti garis aliran.
• Mixed Mode: peta medan skalar dengan medan vektor overlay.
• Data yang hilang ditangani dan tidak mengganggu dengan garis aliran.
• Generasi Scalable Vector Graphics (SVG) file, yang dengan mudah dapat diedit dan convertible sambil menjaga kualitas terbaik untuk dimasukkan dalam sebuah artikel ilmiah PDF.
• Palet warna ini dirancang sehingga aliran seragam dibaca bila dicetak sebagai skala abu-abu.
Gambar 3.3 Peta suhu dengan medan kecepatan overlay, dalam aliran granular.
Anda dapat menentukan kolom untuk digunakan dalam kasus file berisi banyak colums. Vsfplot dapat menampilkan peta skalar juga (x, y, value), atau mode campuran dengan medan vektor ditampilkan di atas peta skalar (x, y, v, vy, nilai). Di (x, y, v, vy) mode 4-kolom, nilai-nilai skalar diatur dengan norma-norma vektor. Lihat penggunaan lengkap di bawah. File output diproduksi di Scalable Vector Graphics (SVG) format yang . Anda dapat dengan mudah mengkonversi ke format bitmap (PNG, JPEG ...), format vektor (PS, PDF ...), mengedit file-file ini (termasuk mengekstraksi gambar atau mengubah panah, dll) dengan menggunakan baik gratis / perangkat lunak gratis Inkscape . Format vektor lebih disukai untuk kualitas yang lebih baik dalam artikel ilmiah.
3.1.3 File Output
Bantuan penuh:
vsfplot [- Pilihan args ...] data_file output_base_name
Pilihan dapat ditentukan dalam urutan apapun:
-D [- Data] arg file data, yang juga dapat ditentukan sebagai Parameter pertama gratis pada baris perintah (tidak perlu untuk opsi - data). Ini adalah ascii sederhana file yang multi-kolom, lihat - gunakan. Gunakan khusus nama - untuk stdin.
-O [- output] arg Nama file output dasar, yang juga dapat ditentukan sebagai parameter bebas kedua pada baris perintah (tidak perlu untuk opsi - output). Dua File SVG yang dihasilkan, seseorang base_name.svg untuk warna yang dihasilkan peta / vektor medan, dan lain base_name_legend.svg untuk terkait legenda. Ukuran gambar yang dihasilkan diatur ke jumlah X dan Y nilai-nilai yang berbeda. Jika hal ini tidak tidak sesuai dengan kebutuhan Anda, Anda dapat dengan mudah rescale SVG file dalam editor SVG (tip: mencoba Inkscape), atau penggunaan faktor zoom (lihat di bawah). Jika hal ini tidak cukup Anda harus resample data file Anda sebelum menyerahkannya pada program ini.
Scalable Vector Graphics (SVG) adalah sebuah XML berbasis vektor format gambar untuk grafis dua dimensi dengan dukungan untuk interaktivitas dan animasi. The SVG spesifikasi merupakan standar terbuka yang dikembangkan oleh World Wide Web Consortium (W3C) sejak tahun 1999.
Gambar SVG dan perilaku mereka didefinisikan dalam XML file teks. Ini berarti bahwa mereka dapat dicari, diindeks, scripted , dan dikompresi . Sebagai file XML, SVG gambar dapat dibuat dan diedit dengan editor teks , tetapi lebih sering dibuat dengan perangkat lunak gambar. Semua besar yang modern web browser -termasuk Mozilla Firefox , Internet Explorer , Google Chrome , Opera , dan Safari -memiliki setidaknya beberapa derajat SVG rendering dukungan . SVG telah dikembangkan sejak tahun 1999 oleh sekelompok perusahaan dalam W3C setelah standar bersaing Presisi Graphics Markup Language (PGML, dikembangkan dari Adobe PostScript ) dan Vector Markup Language (VML, dikembangkan dari Microsoft RTF ) diserahkan ke W3C pada tahun 1998. SVG menarik pengalaman dari desain kedua format tersebut. SVG memungkinkan tiga jenis objek grafis: grafis vektor , grafis raster , dan teks. Objek grafis, termasuk PNG dan JPEG raster gambar, dapat dikelompokkan, gaya, berubah, dan composited ke sebelumnya diberikan objek. SVG tidak langsung mendukung z-indeks yang memisahkan urutan gambar dari pesanan dokumen untuk objek tumpang tindih, tidak seperti beberapa bahasa markup vektor lain seperti vml. Teks dapat dalam namespace XML yang cocok untuk aplikasi, yang meningkatkan kemampuan pencarian dan aksesibilitas grafis SVG. The set fitur meliputi bersarang transformasi , kliping jalan , masker alpha , efek filter , benda Template, dan diperpanjang . Sejak tahun 2001, spesifikasi SVG telah diperbarui ke versi 1.1. The SVG Ponsel Rekomendasi memperkenalkan dua profil sederhana dari SVG 1.1, SVG Basic dan SVG kecil, dimaksudkan untuk perangkat dengan mengurangi kemampuan komputasi dan display. Sebuah versi yang disempurnakan dari SVG kecil, disebut SVG kecil 1.2, kemudian menjadi Rekomendasi otonom. Pekerjaan saat ini berlangsung pada SVG 2, yang mencakup beberapa fitur baru selain yang dari SVG 1.1 dan SVG kecil 1.2.
Fungsi
The SVG 1.1 spesifikasi mendefinisikan 14 bidang fungsional atau fitur set:
Jalur
Sederhana atau senyawa garis bentuk yang digambar dengan garis lengkung atau lurus yang dapat diisi, diuraikan, atau digunakan sebagai clipping path . Jalan memiliki coding kompak. Misalnya M (untuk ’memindahkan’) mendahului x angka awal dan y koordinat dan L (line untuk) mendahului titik untuk mana garis harus ditarik. Surat perintah lebih lanjut (C, S, Q, T dan A) mendahului data yang digunakan untuk menarik berbagai Bézier dan elips kurva. Z digunakan untuk menutup jalan. Dalam semua kasus, koordinat mutlak mengikuti perintah huruf kapital dan koordinat relatif digunakan setelah huruf-huruf kecil setara.
Bentuk dasar
Jalur garis lurus dan jalan terdiri dari serangkaian terhubung segmen garis lurus (polylines), serta poligon tertutup, lingkaran dan elips dapat ditarik. Empat persegi panjang dan persegi panjang bulat terpojok juga unsur-unsur standar.
Teks
Teks karakter Unicode termasuk dalam file SVG dinyatakan sebagai XML data karakter. Banyak efek visual yang mungkin, dan spesifikasi SVG secara otomatis menangani teks dua arah (untuk menyusun kombinasi bahasa Inggris dan Arab teks, misalnya), teks vertikal (seperti Cina secara historis ditulis) dan karakter sepanjang jalan melengkung (seperti teks di sekitar tepi Great Seal dari Amerika Serikat ).
Lukisan
Bentuk SVG dapat diisi dan / atau diuraikan (dicat dengan warna, gradien, atau pola). Mengisi bisa buram atau memiliki tingkat transparansi. "Penanda" fitur line-end, seperti panah, atau simbol-simbol yang bisa muncul di simpul dari poligon.
Warna
Warna dapat diterapkan pada semua elemen terlihat SVG, baik secara langsung atau melalui ’mengisi’, ’stroke, dan properti lainnya. Warna ditentukan dengan cara yang sama seperti dalam CSS2 , yaitu menggunakan nama-nama seperti black atau blue , dalam heksadesimal seperti #2f0 atau #22ff00 , dalam desimal seperti rgb(255,255,127) , atau sebagai persentase dari bentuk rgb(100%,100%,50%)
Gradien dan pola
Bentuk SVG dapat diisi atau diuraikan dengan warna solid seperti di atas, atau dengan gradien warna atau dengan pola berulang. Gradien warna dapat linear atau radial (melingkar), dan dapat melibatkan sejumlah warna serta mengulangi. Gradien opacity juga dapat ditentukan. Pola didasarkan pada raster atau vektor objek grafis yang telah ditetapkan, yang dapat diulang dalam x dan / atau y arah. Gradien dan pola dapat animasi dan scripted. Sejak 2008, telah ada diskusi di kalangan pengguna profesional SVG yang baik gradien jerat atau lebih kurva difusi bisa berguna ditambahkan ke spesifikasi SVG. Dikatakan bahwa "representasi sederhana [menggunakan kurva difusi] mampu mewakili efek shading bahkan sangat halus" dan bahwa "gambar kurva Difusi sebanding baik dalam kualitas dan efisiensi coding dengan jerat gradien, tetapi lebih sederhana untuk membuat ( menurut beberapa seniman yang telah menggunakan kedua alat), dan dapat ditangkap dari bitmap secara otomatis. " Draft saat SVG 2 termasuk jerat gradien.
Kliping, masking dan compositing
Elemen grafis, termasuk teks, jalan, bentuk dasar dan kombinasi ini, dapat digunakan sebagai garis besar untuk menentukan baik di dalam dan luar daerah yang dapat dicat (dengan warna, gradien dan pola) secara mandiri. Jalur kliping sepenuhnya buram dan masker semi-transparan yang composited bersama-sama untuk menghitung warna dan opacity dari setiap pixel dari gambar akhir, menggunakan alpha blending.
Filter efek
Artikel utama: efek filter SVG
Interaktivitas
Gambar SVG dapat berinteraksi dengan pengguna dengan berbagai cara. Selain hyperlink seperti yang disebutkan di bawah ini, setiap bagian dari suatu gambar SVG dapat dibuat menerima user interface peristiwa seperti perubahan dalam fokus , klik mouse, scrolling atau zooming gambar dan pointer lain, keyboard dan acara dokumen. Event handler dapat memulai, menghentikan atau mengubah animasi serta script pemicu dalam menanggapi peristiwa tersebut.
Menghubungkan
Gambar SVG dapat berisi hyperlink ke dokumen lain, dengan menggunakan XLink . URL gambar SVG dapat menentukan transformasi geometris dalam fragmen bagian.
Scripting
Semua aspek dari dokumen SVG dapat diakses dan dimanipulasi menggunakan skrip dalam cara yang mirip dengan HTML. Default bahasa scripting ECMAScript (terkait erat dengan JavaScript ) dan ada didefinisikan Document Object Model (DOM) obyek untuk setiap elemen SVG dan atribut. Script diapit <script> elemen. Mereka dapat berjalan dalam menanggapi peristiwa pointer, peristiwa keyboard dan peristiwa dokumen yang diperlukan.
Animasi
Artikel utama: SVG animation Konten SVG dapat animasi menggunakan built-in elemen animasi seperti <animate> , <animateMotion> dan <animateColor> . Konten dapat animasi dengan memanipulasi DOM menggunakan ECMAScript dan bahasa scripting built-in timer. SVG animasi telah dirancang agar kompatibel dengan versi saat ini dan masa depan Synchronized Multimedia Integration Bahasa (SMIL). Animasi dapat terus menerus, mereka bisa loop dan ulangi, dan mereka dapat menanggapi peristiwa pengguna, seperti yang disebutkan di atas.
Font
Seperti dengan HTML dan CSS, teks dalam SVG dapat referensi file font eksternal, seperti sistem font. Jika file font yang diperlukan tidak ada pada mesin di mana file SVG diberikan, teks mungkin tidak muncul sebagaimana dimaksud. Untuk mengatasi keterbatasan ini, teks dapat ditampilkan dalam font SVG, di mana dibutuhkan mesin terbang didefinisikan dalam SVG sebagai font yang kemudian dirujuk dari <text> elemen.
Metadata
Sesuai dengan W3C ’s Web Semantic inisiatif, SVG memungkinkan penulis untuk menyediakan metadata tentang konten SVG. Fasilitas utama adalah <metadata> elemen, dimana dokumen dapat digambarkan dengan menggunakan Dublin Core properti metadata (misalnya judul, pencipta / penulis, subjek, deskripsi, dll). Skema metadata lainnya juga dapat digunakan. Selain itu, SVG mendefinisikan <title> dan <desc> elemen di mana penulis juga dapat memberikan plain-text bahan deskriptif dalam sebuah gambar SVG untuk membantu pengindeksan, pencarian dan pengambilan oleh sejumlah sarana.
Sebuah dokumen SVG dapat menentukan komponen termasuk bentuk, gradien dll, dan menggunakannya berulang-ulang. Gambar SVG juga dapat berisi raster grafik , seperti PNG dan JPEG gambar, dan gambar SVG lanjut.
CONTOH
Kode ini akan menghasilkan kotak hijau dengan garis hitam:
Gambar 3.7 Output Kode SVG
-U [- menggunakan] arg Tentukan kolom yang digunakan untuk merencanakan, standar adalah 01:02:03 untuk file 3-kolom, 1:2:3:4 untuk File-kolom keempat, dan 1:2:3:4:5 sebaliknya. Itu nilai pertama menunjukkan kolom yang memegang X koordinat, nilai kedua Y koordinat. Program ini mengasumsikan X dan data Y secara teratur spasi, mungkin dengan nilai-nilai yang hilang. Jika hanya tiga nilai-nilai yang ditentukan peta warna skalar dibangun. Jika 4 nilai ditentukan medan vektor dibangun menggunakan nilai ketiga dan keempat sebagai vektor koordinat pada setiap X, Y posisi, dan warnanya diatur sesuai dengan norma vektor. Jika nilai kelima diberikan kemudian digunakan untuk membangun skalar peta warna, sedangkan bidang 3 dan 4 masih digunakan sebagai vektor koordinat untuk merencanakan panah di atas dari peta itu.
-X [- xrange] arg Kisaran nilai X, ditetapkan sebagai min: max. Default-nya adalah menggunakan min dan max dalam file. Nilai data di luar kisaran ini diabaikan.
-Y [- yrange] arg Kisaran nilai Y, ditetapkan sebagai min: max. Default-nya adalah menggunakan min dan max dalam file. Nilai data di luar kisaran ini diabaikan.
-R [- scalar_range] arg Kisaran data skalar, ditetapkan sebagai min: max. Default-nya adalah menggunakan min dan max dalam file, tetapi Anda dapat menentukan rentang yang berbeda, misalnya memiliki warna sebanding di angka yang berbeda. Nilai di luar rentang dijepit ke min / max.
-A [- arrows_range] arg Kisaran panjang panah untuk data vektor, ditetapkan sebagai min: max. Standarnya adalah untuk mengatur panah vektor bernorma median setengah grid ukuran. Berikut min dan max menentukan norma di bawah ini yang ada panah ditampilkan, dan norma di atas mana panah dijepit dengan ukuran grid, dengan rata-rata set ke setengah ukuran grid. Pilihan ini terutama berguna untuk memiliki sebanding panah panjang di angka yang berbeda
-B [- boundary_values] Ada satu pixel per nilai, teratur spasi. Default adalah untuk menetapkan setiap nilai di pusat pixel. Jika opsi ini diatur, min data dan max sesuai ke kiri / rendah batas-batas yang pertama dan terakhir piksel.
-Z [- zoom] arg Jika set, setiap nilai dalam file data diduplikasi yang berkali-kali sepanjang X dan Y arah. Ini efektif membesar piksel. Hanya nilai integer diperbolehkan, tidak ada interpolasi dilakukan, lihat - Output di atas.
-C [- config] arg Jika ditentukan, menambahkan semua parameter dari ini file konfigurasi di samping baris perintah argumen. Sintaks file satu option = nilai per line, # adalah komentar dan baris kosong akan diabaikan. Dalam hal nilai digandakan, baris perintah argumen diutamakan.
-S [- silent] Jangan menampilkan pesan peringatan.
-H [- help] Tampilan bantuan ini
3.1.4 Source Code
/* This file is part of the simple Vector Field Plotter (vfplot) project
Written by Nicolas Brodu <nicolas.brodu@numerimoire.net>
This library is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation;
either version 2.1 of the License, or (at your option) any later version.
This library is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY;
without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details.
You should have received a copy of the GNU Lesser General Public License along with this library; if not, write to the Free Software Foundation, Inc.,
51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
*/
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include <set>
#include <limits>
#include <algorithm>
#include <boost/program_options.hpp>
#include <boost/tokenizer.hpp>
#include <math.h>
#include <stdlib.h>
#include <stdio.h>
#include "image_producer.hpp"
#include "fast_atof_next_token.h"
// C I/O routines + our own real number converter are much faster !
#include <stdlib.h>
// Windows Hacks needed to compile on that "OS"
#ifdef WHACK
// implement the spec with minimal compliance for our needs...
ssize_t getline(char **lineptr, size_t *n, FILE *stream) {
static const int chunck = 80;
if (*lineptr==0) {
*lineptr = (char*)malloc(chunck);
*n = chunck;
}
int offset = 0;
while (true) { int c = fgetc(stream);
if (c==EOF) return -1;
if (offset>=*n) { *n += chunck;
*lineptr = (char*)realloc(*lineptr,*n);
if (!*lineptr) return -1;
// out of mem, shall set errno... }
(*lineptr)[offset++]=(char)c;
if (c==’\n’) break;
}
// terminal 0
if (offset>=*n) { *n += chunck; *lineptr = (char*)realloc(*lineptr,*n);
if (!*lineptr) return -1;
// out of mem, shall set errno... } (*lineptr)[offset]=0; return offset; }
#endif
using namespace std; namespace po = boost::program_options;
int main(int argc, char** argv) {
string configfilename, datafilename, outputfilename, fields, image_size, xrange, yrange, scalar_range, arrows_range;
bool outer_boundaries = false
; int zoomfactor = 1;
po::options_description optionsdesc("Vector (and scalar) field plotter.\nUsage: vfplot [--options args ...] data_file output_base_name\n\nOptions can be specified in any order");
optionsdesc.add_options()
("data,d", po::value(&datafilename)->default_value(""), "The data file, which can also be specified as the first free parameter on the command line (no need for the --data option). This is a simple ascii multi-column file, see --using. Use the special name - for stdin.")
("output,o", po::value(&outputfilename)->default_value(""), "The output files base name, which can also be specified as the second free parameter on the command line (no need for the --output option). Two SVG files are generated, one is base_name.svg for the generated color map / vector field, and the other is base_name_legend.svg for the associated legend. The size of the generated image is set to the number of distinct X and Y values. If this does not suit your needs you may easily rescale the SVG file in a SVG editor (tip: try Inkscape), or use the zoom factor (see below). If this is not enough you’ll have to resample your data file before passing it to this program.")
("using,u", po::value(&fields)->default_value(""), "Specify which columns to use for plotting, default is 1:2:3 for a 3-column file, 1:2:3:4 for a fourth-column file, and 1:2:3:4:5 otherwise. The first value indicate which column holds the X coordinates, the second value the Y coordinates. The program assumes the X and Y data are regularly spaced, possibly with missing values. If only three values are specified a scalar color map is built. If 4 values are specified a vector field is built using the third and fourth values as the vector coordinates at each X,Y position, and the color is set according to the vector norm. If a fifth value is given then it is used for building a scalar color map, while fields 3 and 4 are still used as vector coordinates for plotting the arrows on top of that map.")
("xrange,x", po::value(&xrange)->default_value(""), "The range of the X values, specified as min:max. The default is to use the min and max in the file. Data values outside this range are ignored.")
("yrange,y", po::value(&yrange)->default_value(""), "The range of the Y values, specified as min:max. The default is to use the min and max in the file. Data values outside this range are ignored.")
("scalar_range,r", po::value(&scalar_range)->default_value(""), "The range of the scalar data, specified as min:max. The default is to use the min and max in the file, but you can specify a different range, for example to have comparable colors across different figures. Values outside the range are clamped to the min/max.")
("arrows_range,a", po::value(&arrows_range)->default_value(""), "The range of the arrow lengths for the vector data, specified as min:max. The default is to set the arrow of a median normed vector to half the grid size. Here min and max specify the norm below which no arrow is displayed, and the norm above which the arrow is clamped to the grid size, with the average set to half the grid size. This option is mainly useful to have comparable arrow lengths across different figures")
("boundary_values,b", "There is one pixel per value, regularly spaced. Default is to set each value at a pixel center. If this option is set, the data min and max correspond to the left/low boundaries of the first and last pixels.")
("zoom,z", po::value(&zoomfactor)->default_value(1,""), "If set, each value in the data file is duplicated that many times along the X and Y directions. This effectively enlarges pixels. Only integer values are allowed, no interpolation is performed, see --output above.")
("config,c", po::value(&configfilename)->default_value(""), "If specified, add all parameters from this configuration file in addition to the command-line arguments. The file syntax is one option=value per line, # are comments and blank lines are ignored. In case of duplicated values, the command-line arguments take precedence.")
("silent,s", "Do not display warning messages.")
("help,h","Display this help") ; po::positional_options_description positionaloptions;
positionaloptions.add("data", 1).add("output", 1);
po::variables_map args;
try
{ po::parsed_options parsedopts = po::command_line_parser(argc, argv).
options(optionsdesc).positional(positionaloptions).allow_unregistered().run();
vector<string> unrecopts = po::collect_unrecognized(parsedopts.options, po::exclude_positional);
if (!unrecopts.empty()) { cout << "Warning: Unrecognized options:" << endl;
for (auto opt : unrecopts) cout << " " << opt << endl;
}
po::store(parsedopts, args);
po::notify(args);
} catch (exception& e) { cout << optionsdesc << endl; cout << e.what() << endl;
return 1;
}
if (!configfilename.empty()) { ifstream configfile(configfilename.c_str());
if (!configfile) { cout << "Warning: Cannot find config file: " << configfilename << endl;
}
else { try { po::parsed_options parsedopts = po::parse_config_file(configfile, optionsdesc, true);
vector<string> unrecopts = po::collect_unrecognized(parsedopts.options, po::exclude_positional);
if (!unrecopts.empty()) { cout << "Warning: Unrecognized options:" << endl;
for (auto opt : unrecopts) cout << " " << opt << endl; } po::store(parsedopts, args); po::notify(args);
}
catch (exception& e) { cout << optionsdesc << endl; cout << e.what() << endl; return 1;
} configfile.close(); } } if (args.count("help")) { cout << optionsdesc << endl; return 0;
}
bool verbose = true; if (args.count("silent")) verbose = false;
if (args.count("boundary_values")) outer_boundaries = true;
if (outputfilename.empty()) { cerr << optionsdesc << endl;
cerr << "Error: No output file specified!" << endl; return 1; } FILE* datafile = stdin; if (datafilename!="-") datafile = fopen(datafilename.c_str(), "r");
if (!datafile) { cerr << optionsdesc << endl; cerr << "Error: Cannot open data file!" << endl;
return 1; }
vector<vector<double>> data; int linenum = 0;
char* line = 0; size_t linelen = 0; int num_read = 0;
int num_data_per_line = -1; while ((num_read = getline(&line, &linelen, datafile)) != -1) { ++linenum; // ignore comments and eof if (linelen==0 || line[0]==’#’) continue;
// ignore blank lines char* x = line; while ((*x==’ ’)||(*x==’\t’)||(*x==’\n’)||(*x==’\r’)) ++x;
if (*x==0) continue; data.resize(data.size()+1); while(*x!=0) { double value = fast_atof_next_token(x);
data.back().push_back(value); } if (num_data_per_line==-1) num_data_per_line = data.back().size();
else if (num_data_per_line != data.back().size()) { if (verbose) cout << "Warning: Inconsistent number of data values line " << linenum << " (" << data.back().size() << ", should be " << num_data_per_line << ")" << endl;
// ensure no out-of-range condition even in this case if (data.back().size()<num_data_per_line) data.back().resize(num_data_per_line); } } fclose(datafile); if (num_data_per_line<3) { cerr << optionsdesc << endl; cerr << "Error: Invalid data file: need at least 3 columns per line." << endl; return 1; }
if (fields.empty()) { if (num_data_per_line==3) fields="1:2:3";
else if (num_data_per_line==4) fields="1:2:3:4"; else fields="1:2:3:4:5"; } typedef boost::tokenizer<boost::char_separator<char> > tokenizer;
boost::char_separator<char> separator(":");
tokenizer columntokens(fields, separator); vector<int> column;
for (tokenizer::iterator it = columntokens.begin();
it != columntokens.end(); ++it) { column.push_back(atoi(it->c_str())-1);
// account for 1->0 for the indexing if (column.back()<0 || column.back()>=num_data_per_line) { cerr << optionsdesc << endl;
cerr << "Error: Invalid column number in the --using argument." << endl; return 1;
} } if
(column.size()<3 || column.size()>5) { cerr << optionsdesc << endl;
cerr << "Error: Invalid columns specification in the --using argument, need between 3 and 5 values." << endl;
return 1;
}
int x = column[0]; int y = column[1]; int vx = -1, vy = -1, s = -1;
if (column.size()==3) s = column[2]; else { vx=column[2]; vy=column[3];
if (column.size()==5) s = column[4]; } if (!xrange.empty()) { tokenizer minmaxtokens(xrange, separator);
tokenizer::iterator it = minmaxtokens.begin(); double dmin, dmax; bool hasrange = true;
if (it != minmaxtokens.end()) dmin = atof((*it++).c_str()); else hasrange = false;
if (it != minmaxtokens.end()) dmax = atof((*it++).c_str()); else hasrange = false;
if (hasrange) { int ndata = data.size(); for (int i=0; i<ndata;) {
if (data[i][x]<dmin || data[i][x]>dmax) { data[i].swap(data[--ndata]);
} else ++i; } data.resize(ndata); }
else { if (verbose) cout << "Warning: invalid xrange specified, ignored." << endl; } }
if (!yrange.empty()) { tokenizer minmaxtokens(yrange, separator);
tokenizer::iterator it = minmaxtokens.begin(); double dmin, dmax; bool hasrange = true;
if (it != minmaxtokens.end()) dmin = atof((*it++).c_str()); else hasrange = false;
if (it != minmaxtokens.end()) dmax = atof((*it++).c_str()); else hasrange = false;
if (hasrange) { int ndata = data.size(); for (int i=0; i<ndata;) {
if (data[i][y]<dmin || data[i][y]>dmax) { data[i].swap(data[--ndata]);
} else ++i; } data.resize(ndata); } else { if (verbose) cout << "Warning: invalid yrange specified, ignored." << endl;
}
}
set<double> xvalues, yvalues; double minx = numeric_limits<double>::max();
double maxx = -numeric_limits<double>::max(); double miny = numeric_limits<double>::max()
; double maxy = -numeric_limits<double>::max(); for(auto v : data) { xvalues.insert(v[x]);
minx = min(minx,v[x]); maxx = max(maxx,v[x]); yvalues.insert(v[y]); miny = min(miny,v[y]); maxy = max(maxy,v[y]); }
int nx = xvalues.size(); int ny = yvalues.size();
// outer boundaries: from minx to maxx at the pixels boundaries
// maxx included in the last pixel
// default mode: one pixel per distinct value, assume regularly spaced
// minx is at the center of the first pixel, maxx also /
/ | minx | ... | ... | maxx |
// ex: 4 pixels, nx=4, with minx=18, maxx=24, maxx-minx=6.
// (maxx-minx) = dx * (nx-1); double dx = 1
; double dy = 1; if (nx>1) dx = (maxx-minx) / (nx-1);
if (ny>1) dy = (maxy-miny) / (ny-1);
ImageProducer ip(nx*zoomfactor,ny*zoomfactor,dx/zoomfactor,dy/zoomfactor,minx-(outer_boundaries?0:(0.5*dx)),miny-(outer_boundaries?0:(0.5*dy)));
for(auto v : data) { int xi = max(0,min(nx-1,(int)round((v[x]-minx)/dx)));
int yi = max(0,min(ny-1,(int)round((v[y]-miny)/dy)));
for (int zxi = 0; zxi < zoomfactor; ++zxi) for (int zyi = 0; zyi < zoomfactor; ++zyi)
if (vx==-1) ip.plot(xi*zoomfactor+zxi,yi*zoomfactor+zyi,v[s]);
else if (s==-1) ip.vfplot(xi*zoomfactor+zxi,yi*zoomfactor+zyi,v[vx],v[vy]);
else ip.vfplot(xi*zoomfactor+zxi,yi*zoomfactor+zyi,v[vx],v[vy],v[s]); }
if (!arrows_range.empty()) { tokenizer minmaxtokens(arrows_range, separator);
tokenizer::iterator it = minmaxtokens.begin(); double dmin, dmax; bool hasrange = true;
if (it != minmaxtokens.end()) dmin = atof((*it++).c_str()); else hasrange = false;
if (it != minmaxtokens.end()) dmax = atof((*it++).c_str()); else hasrange = false;
if (hasrange) ip.set_arrows_range(dmin,dmax);
else { if (verbose) cout << "Warning: invalid arrows range specified, using median value from the data" << endl;
} } if (scalar_range.empty()) ip.save(outputfilename);
else { tokenizer minmaxtokens(scalar_range, separator);
tokenizer::iterator it = minmaxtokens.begin(); double dmin, dmax; bool hasrange = true;
if (it != minmaxtokens.end()) dmin = atof((*it++).c_str()); else hasrange = false;
if (it != minmaxtokens.end()) dmax = atof((*it++).c_str()); else hasrange = false;
if (hasrange) ip.save(outputfilename,dmin,dmax); else { if (verbose) cout << "Warning: invalid scalar range specified, using min/max from the data" << endl; ip.save(outputfilename); } }
return 0;
}
3.2 KOMPLEKSITAS PENINGKATAN UKURAN
Algoritma incremental sederhana dikenal juga terlihat seperti DDA (Digital Differential Analyzer) algoritma. The pricnip algoritma ini didasarkan pada peningkatan berkala dx untuk koordinasi x dan juga dy untuk koordinasi y. Mulai titik adalah salah satu dari titik akhir garis. Karena kita pola raster, meningkat pada arah sumbu akan (memberikan, jika baris cenderung untuk sumbu x adalah arah sumbu x) tepat satu titik.Cara mengikuti. Dalam satu lingkaran kita akan langkah demi langkah menambah koordinasi pada nilai sumbu utama 1 dan untuk mengkoordinasikan pada insiden sumbu menambahkan peningkatan. Jika sumbu x adalah utama, nilai kemiringan m sama. Jika sumbu y maka nilai kemiringan sama 1 / m. Nyata nomor koordinat benda yang ditampilkan harus dibulatkan. Algoritma DDA digunakan untuk perhitungan nilai koordinasi baru sebelum dot.Tujuan dari kode ini adalah untuk memperluas metode untuk membuat tambahan, observasi begitu baru diperhitungkan segera setelah mereka datang: cluster diperbarui, dan perkiraan kompleksitas yang dievaluasi kembali secara efisien. Demikian pula, ada kemungkinan untuk menghapus poin usang dalam kasus sistem non-stasioner dan pengamatan lama telah menjadi tidak konsisten dengan yang baru. Kode ini bersifat otonom (tidak ada ketergantungan eksternal), generik (berlaku untuk semua jenis pengguna), mudah digunakan (lihat di bawah), dan terdiri dalam file header tunggal.
Gambar 3.8 Pseudocode Algoritma Incremental
Contoh :
Contoh pertama ini menunjukkan dasar otomat seluler 1-dimensi (CA) untuk aturan 146, dengan kondisi awal random, dalam dunia siklik. Bagian kiri gambar adalah CA lapangan mentah, bagian kanan menunjukkan algoritma dalam tindakan. Pola-pola yang terdeteksi sulit untuk mengikuti CA lapangan, tapi jelas terlihat di bidang kompleksitas. Hasilnya sebanding dengan plot dalam artikel ini dihitung dengan Cimula . Tahap awal transien telah dihapus dan semua pengamatan kemudian dikumpulkan sebelum komputasi kompleksitas, menggunakan perintah ./CA_Complexity -k200 -n -p6 -f6 -r146 -w400 -t300 -s11
Ini adalah aturan 54 dalam tindakan. Gambar mencakup kondisi awal acak dan pengamatan ditambahkan baris demi baris, bertahap: Algoritma cepat "belajar" pola latar belakang, yang blanked keluar sebagai "uncomplex". ./CA_Complexity -r54 -w400 -t300
Ini adalah terkenal aturan 110 . kondisi awal Transient yang dilewati, dan ukuran cahaya-kerucut diatur untuk membuat interaksi lebih terlihat. ./CA_Complexity -k500 -n -p6 -f5 -r110 -w400 -t300 -s6
3.2.1 Source Code
#include <iostream> #include <fstream> #include <sstream> using namespace std; #include "CausalStateAnalyzer.h"
#include <stdlib.h>
// For past and future cones. Cell states at t, then at t+-1, t+-2, etc... struct LightCone : public vector<int> {
// map cones to id so distributions only manipulate the id
// distributions are possible with the cones directly too, thanks to templatized // analyzer, but this is faster typedef map<LightCone,int> LightConeMap;
// Implement a lesser_than operator to get O(log(n)) insert on maps bool operator<(const LightCone& cone) {
// use simple lexicographic ordering const int minsize = min(size(), cone.size()); for (int i=0; i<minsize; ++i) { if ((*this)[i] < cone[i]) return true; if ((*this)[i] > cone[i]) return false; }
// elements are equal so far, strict < iff second cone has more elements return size() < cone.size(); }
static LightConeMap conesId;
// returns the id of this light cone, make a new one if necessary the first time int getId() { LightConeMap::iterator myPlace = conesId.find(*this); if (myPlace != conesId.end()) return myPlace->second; return conesId[*this] = ++nextId; // start from 1 }
static int nextId; }; int LightCone::nextId = 0; LightCone::LightConeMap LightCone::conesId;
struct Rule {
int nextState[8];
Rule(unsigned int number) { // convert CA rule notation to state array for (int i=0; i<8; ++i) { nextState[i] = number & 1; number = number >> 1; } }
// apply the rule to the 3 cells that are either 0 or 1 int apply(int left, int center, int right) { return nextState[ (left << 2) | (center << 1) | right ]; } };
// to generate the initial conditions struct RandFunctor { int operator()() { return (rand() >> 17) & 1; // use any bit } };
int main(int argc, char** argv) {
// User-defined variables int past_depth = 5; int future_depth = 3; int rule_number = -1; int seed = 1; float siglevel = 0.04321;
bool quietMode = false; bool columnMode = false; opterr = 0;
int c; while ((c=getopt(argc,argv,"chqp:f:s:r:g:"))!=-1) switch(c) { case ’q’: quietMode = true; break; case ’c’: columnMode = true;
break;
case ’g’: { float arg = (float)atof(optarg);
if (arg!=0.0f) siglevel = arg; break; } case ’p’: { int arg = atoi(optarg);
if (arg!=0) past_depth=arg; break; } case ’f’: { int arg = atoi(optarg);
if (arg!=0) future_depth=arg; break; } case ’s’: { int arg = atoi(optarg);
if (arg!=0) seed=arg; break; } case ’r’: { rule_number=atoi(optarg);
// 0 is valid break; } case ’?’: case ’h’: default: cout << "Usage:\n-p<integer>:
past depth\n-f<integer>: future depth\n-r<integer>: rule number\n-g<float>: chi-square significance level for clustering distributions\n-q: quiet mode\n-s<integer>:
random seed\n-c: Use single column instead of whole cones." << endl; return 0; }
// derived variables int wsize = future_depth*2-1 + (future_depth+past_depth-2)*2;
if (rule_number==-1) rule_number = 110;
// default
if (!quietMode) { std::ios::sync_with_stdio(false);
// GNU specific? cout << "past depth = " << past_depth << endl;
cout << "future depth = " << future_depth << endl; cout << "world size = " << wsize << endl;
cout << "rule number = " << rule_number << endl; cout << "random seed = " << seed << endl;
cout << "significance for clustering = " << siglevel << endl;
if (columnMode) cout << "warning: column mode" << endl; }
srand(seed);
CausalStateAnalyzer<int,int> analyzer(siglevel);
Rule rule(rule_number);
// double-buffering int state1[wsize], state2[wsize]; int* state = state1;
int* nextState = state2;
for (int initial_config = 0; initial_config < (1 << wsize);
++initial_config) { int config = initial_config; for (int i=0; i<wsize; ++i) state[wsize-1-i] = (config >> i) & 1;
LightCone plc; int center = wsize/2;
// wsize necessarily odd, OK int side = past_depth - 1;
// spacial extent of light cone on each side if (columnMode) side = 0;
// init state in plc for (int i=center-side; i<=center+side; ++i) plc.push_back(state[i]);
// other states in plc int t; for (t=1; t<past_depth; ++t) {
// update state where possible for (int i=t; i<wsize-t; ++i) nextState[i] = rule.apply(state[i-1], state[i], state[i+1]); swap(state, nextState);
// update plc if (!columnMode) --side; for (int i=center-side; i<=center+side; ++i) plc.push_back(state[i]); }
assert(side==0);
// create flc LightCone flc;
// present is in flc as well flc.push_back(center);
for (; t<past_depth+future_depth-1; ++t) {
// update state where possible for (int i=t; i<wsize-t; ++i) nextState[i] = rule.apply(state[i-1], state[i], state[i+1]); swap(state, nextState);
// update flc if (!columnMode) ++side; for (int i=center-side; i<=center+side; ++i) flc.push_back(state[i]); }
analyzer.addObservation(plc.getId(), flc.getId());
// for (int i=0; i<wsize; ++i) cout << state[i];
// cout << endl;
}
analyzer.commitObservations();
if (!quietMode) { cout << "Global complexity: " << analyzer.getGlobalComplexity() << endl;
cout << "Number of states: " << analyzer.clusters.size() << endl;
cout << "Number of observed pasts: " << analyzer.observedDistributions.size() << endl;
#ifdef MESINCOM_DEBUG for (unsigned int i=0; i<analyzer.clusters.size(); ++i) { int nf = analyzer.clusters[i]->distribution.size();
cout << "nf="<<nf<<"("<<analyzer.clusters[i]->distribution.total<<"): ";
for (int f=0; f<nf;++f) { int flcid = analyzer.clusters[i]->distribution[f].first; int cf = analyzer.clusters[i]->distribution[f].second;
cout <<flcid; cout << "("<<cf<<") "; } cout << endl; } analyzer.assertNoClusterMatch(); #endif }
else cout << "Rule=" << rule_number << ", complexity=" << analyzer.getGlobalComplexity() << endl;
return 0; }
Panduan API Cepat
1. Tentukan jenis light cone Anda: apa yang mewakili masa lalu dan masa depan sistem anda. Sebagai contoh, ID integer. Kemudian membuat objek analyzer: CausalStateAnalyzer<int,int> analyzer;
2. Memantau masa lalu dan masa depan sistem anda dan memberikan diamati (masa lalu, masa depan) pasangan. analyzer.addObservation(past, future);
3. Komit pengamatan ketika Anda berpikir Anda memiliki cukup dari mereka. Hal ini dapat dilakukan setelah masing-masing pasangan jika Anda ingin, atau setelah Anda telah mengumpulkan semua pengamatan, atau kapan pun Anda suka. analyzer.commitObservations();
4. Pada titik itu, kompleksitas siap: Kompleksitas lokal dikembalikan sebagai vektor dengan satu entri untuk setiap pasangan pengamatan Anda berikan, agar: vector<float>& complexities = analyzer.getComplexities(); Kompleksitas global jumlah informasi dalam bit yang akan diperlukan untuk mengkodekan semua negara kausal: float globalComplexity = analyzer.getGlobalComplexity();
Sekarang Anda dapat loop untuk langkah 2 untuk terus memberikan pengamatan, dll Hanya ingat untuk melakukan pengamatan sebelum membaca kompleksitas baru.
Opsional:
A. Anda dapat menghapus pengamatan sebelumnya, yang sangat membantu bagi (perlahan-lahan) sistem non-stasioner di mana kompleksitas berkembang dari waktu ke waktu. analyzer.removeObservation(too_old_past, too_old_future);
B. Anda juga bisa menelepon "getScaledComplexities" fungsi untuk memiliki nilai-nilai dalam [0 .. 1], skala menggunakan diamati min / max. Hal ini berguna untuk membuat gambar grayscale misalnya. vector<float>& complexities = analyzer.getScaledComplexities();
3.3 SPHERICAL NEIGHBORHOOD QUERIES
Ini merupakan algoritma untuk mencari tetangga untuk benda titik yang bisa bebas bergerak dan tidak memiliki posisi yang telah ditetapkan. Permintaan lingkup terdiri dari lokasi pusat dan radius tertentu di mana benda-benda di dekatnya harus ditemukan. Space didiskritisasi dalam sel kubik. Algoritma ini memperkenalkan skema pengindeksan yang memberikan daftar semua sel yang membentuk bola query, untuk setiap radius dan setiap lokasi pusat. Ini tambahan dapat mengambil di account kedua wilayah siklik dan non-siklik yang menarik. Menemukan hanya tetangga terdekat K-alami manfaat dari pengindeksan permintaan sphere dengan menjalankan melalui daftar sel dari pusat dalam meningkatkan jarak, dan prematur berhenti ketika tetangga K telah ditemukan.
Gambar 3.12 Spherical Neighborhood Queries
Menemukan tetangga dari suatu titik tertentu adalah masalah umum yang masih menjadi topik utama penelitian.
Terdapat berbagai macam kebutuhan aplikasi, yang dapat diklasifikasikan dalam kategori berikut:
1. Titik data statis atau dinamis.
2. Permintaan adalah perkiraan atau sama persis.
3. Semua poin harus dikembalikan atau hanya yang terdekat.
Masalah statis biasanya ditemukan untuk Misalnya dalam sistem geolocalization dan mereka memungkinkan teknik pra-sortasi, biasanya berbasis pohon. kira-kira query biasanya kompromi untuk penanganan besar set data dimensi, dengan domain aplikasi khususnya untuk visi komputer. Graphics aplikasi seperti rekonstruksi mesh dari titik awan sangat bergantung pada menemukan tetangga K-terdekat untuk masing-masing titik, sedangkan game mungkin perlu untuk menemukan semua tetangga pemain diberikan dalam radius tertentu untuk messaging tujuan. Algoritma yang disajikan di sini berkonsentrasi pada objek yang dinamis, yang posisi tidak bisa diketahui sebelumnya dan perubahan dengan waktu. Tipikal contoh aplikasi dari algoritma ini adalah multi-agent simulasi di mana semua agen dapat bergerak, dan tetangga untuk setiap agen perlu ditemukan pada saat run-time untuk AI. Secara umum algoritma ini dirancang untuk menangani kasus di mana operasi database update dilakukan sesering atau lebih dari operasi query.
Dalam contoh sebelumnya update diperlukan untuk setiap gerakan objek, sedangkan query dilakukan hanya untuk AI. Situasi ini persis kebalikan seperti untuk kasus geolocalization atau besar database query perkiraan, di mana penggunaan khas adalah untuk meminta benda-benda di dekatnya tetapi benda-benda itu sendiri relatif statis dari waktu ke waktu. Dalam skenario seperti teknik berbasis pohon (seperti kd-tree) melakukan buruk: Mengubah posisi objek ’menurunkan sifat pohon, yang kemudian harus dibangun kembali, dan ini adalah operasi yang mahal (dan lebih daripada untuk update konstan-waktu disajikan di bawah ini dalam kasus).
Memelihara daftar tetangga K-terdekat untuk ponsel agen masih layak dengan teknik berbasis pohon, seperti pada algoritma yang diusulkan oleh Li et al, meskipun dalam hal ini lintasan dari setiap objek dalam setiap secara lokal benda lain perlu dihitung. bahkan maka update pohon masih tidak dapat dihindari dan pasti tidak konstan-waktu. Bahkan, untuk dinamis objek situasi, metode pembagian spasial bin-kisi memiliki sifat terbaik: Pembaruan konstan-waktu tata ruang database ketika sebuah benda bergerak, dan permintaan diamortisasi waktu pencocokan hanya sebagian kecil dari semua benda rata-rata. Algoritma yang disajikan di sini dapat dilihat sebagai perbaikan atas bin-kisi subdivisi spasial Metode. Kasus selama tiga dimensi digambarkan dalam artikel ini dan ditangani oleh implementasi referensi, meskipun teknik yang disajikan dalam dokumen ini generik dan berlaku untuk konteks lain juga.
3.3.1 Source Code
struct Agent { / / Menempatkan bidang dan metode di sini
int number; / / Referensi yang berguna, ID Agent ini
ObjectProxy <Agent> * Proxy; }; ...
/ / Tentukan dunia non-siklik dengan diskritisasi 16x16x16
typedef NeighborhoodHandler <Agent,4,4,4,false,false,false> NH;
/ / Ukuran sel 6,25 unit sehingga daerah bunga meliputi 0 hingga 100 dalam setiap dimensi
NH nh (0,0,0,6.25); ...
/ / Masukkan beberapa objek
agent1.proxy = nh.insert (x1, y1, z1, & agent1, ProxiedObjectRemapper <Agent> ());
agent2.proxy = nh.insert (x2, y2, z2, & agent2, ProxiedObjectRemapper <Agent> ()); ...
/ / Cari semua benda dalam jarak d dari titik di (x, y, z)
vector <Agent*> tetangga; nh.findNeighbors (x, y, z, d, tetangga);
/ / Cari objek terdekat dari agent1 (tapi tidak sendiri), dalam jarak maksimum d
NearestNeighbor <Agent> tetangga; nh.findNearestNeighbor (agent1.proxy, d, & tetangga);
cout << "Para tetangga terdekat dari agent1 adalah jumlah agen" << Neighbor.object-> jumlah << endl;
cout << "Hal ini pada d ^ 2 =" << Neighbor.squaredDistance << "Jauh dari agent1" << Endl;
Source Code
/* Neighand: Neighborhood Handling library
The goal of this project is to find 3D neighbors efficiently. Read the documentation contained in the article
"Query Sphere Indexing for Neighborhood Requests" for details.
This program checks that the library works as intended
Nicolas Brodu, 2006/7 Code released according to the GNU GPL, v2 or above. */
#include <iostream> #include <vector> #include <algorithm> #include <sstream> using namespace std;
#include <math.h>
#include "neighand.h" using namespace neighand;
struct Agent { int number; FloatType x,y,z; // to find back the position for SQ ObjectProxy<Agent>* proxy; };
// Declare how many agents to put in the DB const int Nagents = 10000;
Agent* agents; vector<int> nhneighbors, sqneighbors; FloatType sizeX, sizeY, sizeZ;
template <bool wrapX, bool wrapY, bool wrapZ> inline FloatType squaredDistance(FloatType dx,FloatType dy,FloatType dz);
template <> inline FloatType squaredDistance<false,false,false>
(FloatType dx,FloatType dy,FloatType dz) { return dx*dx+dy*dy+dz*dz; }
template <> inline FloatType squaredDistance<true,true,false>
(FloatType dx,FloatType dy,FloatType dz)
{ dx = remainderf(dx, sizeX); dy = remainderf(dy, sizeY);
return dx*dx+dy*dy+dz*dz; }
template <> inline FloatType squaredDistance<true,true,true>
(FloatType dx,FloatType dy,FloatType dz)
{ dx = remainderf(dx, sizeX); dy = remainderf(dy, sizeY);
dz = remainderf(dz, sizeZ); return dx*dx+dy*dy+dz*dz; }
struct VectorFunctor { vector<int>* nbagents; VectorFunctor(vector<int>* nb)
: nbagents(nb) {} void operator()
(Agent* agent) { nbagents->push_back(agent->number); } };
int32_t getULPDiff(FloatConverter x, FloatConverter y) { return x.i - y.i; }
void help() { cout << "Usage:\n" "-s seed Use the given random seed\n" "-u
ULP Use the given Units of Least Precision tolerance for float comparisons\n" "-h This help\n" << flush; }
int main(int argc, char** argv) {
unsigned long seed = 0; int32_t ULP_precision = 0;
int c; while ((c=getopt(argc,argv,"hs:u:"))!=-1) switch(c)
{ case ’s’: seed = atoi(optarg); break; case ’u’:
ULP_precision = atoi(optarg); break; default: help(); return 0; }
if (seed==0) seed = time(0);
cout << "Using random seed: " << seed << "
(pass as argument to reproduce this test)." << endl;
if (ULP_precision) cout << "Using " << ULP_precision
<<" ULP for float comparison tolerance." << endl;
else cout << "Using exact match for float comparisons, see the -u option for setting a tolerance."
<< endl; srand(seed);
// 32x32x32 bloc, from 10 to 54.8 (random values) typedef NeighborhoodHandler
<Agent,5,5,5,CONSISTENCY_TEST_WRAP> NH; NH nh(10.f, 10.f, 10.f, 1.4f)
;//, "consistency.bin"); sizeX = 44.8; sizeY = 44.8; sizeZ = 44.8;
agents = new Agent[Nagents];
// Put them in +- 10 units on each side are outside for (int i=0; i<Nagents; ++i)
{ agents[i].number = i; agents[i].x = 64.8 * (rand() / (RAND_MAX + 1.0f));
agents[i].y = 64.8 * (rand() / (RAND_MAX + 1.0f));
agents[i].z = 64.8 * (rand() / (RAND_MAX + 1.0f));
// Insert in NH agents[i].proxy = nh.insert(agents[i].x, agents[i].y, agents[i].z,
&agents[i], ProxiedObjectRemapper<Agent>()); }
int Nqueries = 10000; int NmovesPerQuery = 5000; bool globalFailed = false;
int numULPdiff = 0;
// Now call the callbackFunction on random queries with both, and compare
// Use stl for sorting algorithms for (int i=0; i<Nqueries; ++i) {
// First randomize the positions.
// This tests that the move operation works as intended for (int j=0; j<NmovesPerQuery; ++j)
{ int a = rand() % Nagents; agents[a].x = 64.8 * (rand() / (RAND_MAX + 1.0f));
agents[a].y = 64.8 * (rand() / (RAND_MAX + 1.0f));
agents[a].z = 64.8 * (rand() / (RAND_MAX + 1.0f));
nh.update(agents[a].proxy, agents[a].x, agents[a].y, agents[a].z); }
// Now perform a query
// choose a distance that covers all case (completely out, intersect, englobes all)
FloatType distance = 64.8f * (rand() / (RAND_MAX + 1.0f));
FloatType distSquared = distance * distance;
// choose point anywhere, possibly out FloatType x = 64.8f * (rand() / (RAND_MAX + 1.0f));
FloatType y = 64.8f * (rand() / (RAND_MAX + 1.0f));
FloatType z = 64.8f * (rand() / (RAND_MAX + 1.0f));
// Pass a build list as argument nhneighbors.clear();
sqneighbors.clear();
NearestNeighbor<Agent> closest; NearestNeighbor<Agent> knn[20];
int knnfound;
QueryMethod methods[4] = {Sphere, Cube, NonEmpty, Brute};
const char* methodNames[4] = {"Sphere", "Cube", "NonEmpty", "Brute"};
int methodIdx = rand()%4;
QueryMethod method = methods[methodIdx]; nh.setQueryMethod(method);
int closestSelected = rand()%3; switch (closestSelected) {
// find all neighbors case 0: nh.applyToNeighbors(x, y, z, distance, VectorFunctor(&nhneighbors));
// simple query algo for (int a = 0; a<Nagents; ++a)
{ if (squaredDistance<CONSISTENCY_TEST_WRAP>
(agents[a].x-x, agents[a].y-y, agents[a].z-z)<=distSquared) { sqneighbors.push_back(a); } } break;
// Nearest neighbor only. case 1: if (nh.findNearestNeighbor(x, y, z, distance, &closest)!=0)
nhneighbors.push_back(closest.object->number);
{ FloatType dmin = distSquared; int amin = -1;
// simple query algo for (int a = 0; a<Nagents; ++a)
{ FloatType dsq=squaredDistance<CONSISTENCY_TEST_WRAP>
(agents[a].x-x, agents[a].y-y, agents[a].z-z); if (dsq <= dmin) { dmin = dsq; amin = a; } }
if (amin!=-1) sqneighbors.push_back(amin); } break;
// find the K nearest neighbors, reasonable random K range case 2:
{ int N = 1+(rand()%20); knnfound = nh.findNearestNeighbors(x, y, z, distance, knn, N);
for (int i=0; i<knnfound; ++i) nhneighbors.push_back(knn[i].object->number);
// sq now { for (int i=0; i<N; ++i) knn[i].squaredDistance = numeric_limits<float>::max();
int nfound = 0; for (int a = 0; a<Nagents; ++a)
{ FloatType dsq=squaredDistance<CONSISTENCY_TEST_WRAP>
(agents[a].x-x, agents[a].y-y, agents[a].z-z); if (dsq <= distSquared)
{ if (++nfound>N) nfound=N;
NearestNeighbor<Agent> currentObject; currentObject.squaredDistance = dsq;
currentObject.object = &agents[a];
// keep only the min. don’t reduce search distance here for (int i=0; i<nfound; ++i)
if (dsq < knn[i].squaredDistance)
{ NearestNeighbor<Agent> tmp = knn[i]; knn[i] = currentObject; currentObject = tmp;
} } } for (int i=0; i<nfound; ++i) sqneighbors.push_back(knn[i].object->number); } break; } }
// showLists(x,y,z,distance);
// post-process: sort the integers for comparison sort(nhneighbors.begin(), nhneighbors.end());
sort(sqneighbors.begin(), sqneighbors.end());
bool failed = false;
// Automated test unsigned int nhidx = 0, sqidx = 0;
stringstream sout; while ((nhidx < nhneighbors.size()) && (sqidx < sqneighbors.size()))
{ if (nhneighbors[nhidx] == sqneighbors[sqidx]) {++nhidx; ++sqidx; continue;}
if (nhneighbors[nhidx] < sqneighbors[sqidx])
{ FloatType dsq = squaredDistance<CONSISTENCY_TEST_WRAP>
(x-agents[nhneighbors[nhidx]].x, y-agents[nhneighbors[nhidx]].y, z-agents[nhneighbors[nhidx]].z);
int32_t ulp = getULPDiff(dsq, distance*distance);
if (abs(ulp)>ULP_precision) failed = true; else ++numULPdiff; sout << ulp << "\t"
<< nhneighbors[nhidx] << "\t" << "nh: dsq=
" << dsq << " at (" << agents[nhneighbors[nhidx]].x << ",
" << agents[nhneighbors[nhidx]].y<<",
" <<agents[nhneighbors[nhidx]].z << ")" <<endl; ++nhidx; continue; }
FloatType dsq = squaredDistance<CONSISTENCY_TEST_WRAP>
(x-agents[sqneighbors[sqidx]].x, y-agents[sqneighbors[sqidx]].y, z-agents[sqneighbors[sqidx]].z);
int32_t ulp = getULPDiff(dsq, distance*distance); if (abs(ulp)>ULP_precision) failed = true;
else ++numULPdiff; sout << ulp << "\t" << sqneighbors[sqidx] << "\t" << "sq: dsq="
<< dsq << " at (" << agents[sqneighbors[sqidx]].x << ",
" << agents[sqneighbors[sqidx]].y<<", " <<agents[sqneighbors[sqidx]].z << ")"
<<endl; ++sqidx; } while (nhidx < nhneighbors.size())
{ FloatType dsq = squaredDistance<CONSISTENCY_TEST_WRAP>
(x-agents[nhneighbors[nhidx]].x, y-agents[nhneighbors[nhidx]].y, z-agents[nhneighbors[nhidx]].z);
int32_t ulp = getULPDiff(dsq, distance*distance);
if (abs(ulp)>ULP_precision) failed = true;
else ++numULPdiff; sout << ulp << "\t" << nhneighbors[nhidx] << "\t" << "nh: dsq="
<< dsq << " at (" << agents[nhneighbors[nhidx]].x << ",
" << agents[nhneighbors[nhidx]].y<<",
" <<agents[nhneighbors[nhidx]].z << ")"
<<endl; ++nhidx; } while (sqidx < sqneighbors.size()) { FloatType dsq = squaredDistance
<CONSISTENCY_TEST_WRAP>(x-agents[sqneighbors[sqidx]]
.x, y-agents[sqneighbors[sqidx]].y, z-agents[sqneighbors[sqidx]].z); int32_t ulp = getULPDiff(dsq, distance*distance);
if (abs(ulp)>ULP_precision) failed = true;
else ++numULPdiff; sout << ulp << "\t"
<< sqneighbors[sqidx] << "\t" << "sq: dsq=" << dsq << " at (" << agents[sqneighbors[sqidx]].x << ",
" << agents[sqneighbors[sqidx]].y<<", " <<agents[sqneighbors[sqidx]].z << ")" <<endl; ++sqidx; }
if (!sout.str().empty()) { cout << "FAILED for " << methodNames[methodIdx] << "
" << (closestSelected?((closestSelected==1)?"
(find closest)":"(find K nearest)"):"(find all)") << ", dsq="<<(distance*distance)<<",
center=("<<x<<", "<<y<<", "<<z<<")"<<endl;
cout << "ULP\tAgent#\tIn (sq/nh) list but not in the other list"
<< endl; cout << sout.str(); globalFailed = true; } }
if (!globalFailed) { cout << Nqueries << " random tests OK";
if (numULPdiff>0) cout << " (" << numULPdiff
<< " discrepancies below or equal to "<< ULP_precision << " ULP)";
else cout << " (perfect match)"; cout << endl; } else
{ cout << endl << "Check FAILED. See the ULP numbers above to check if this is a real failure or a float point comparison discrepancy.
If so, use the -u option to set the units of least precision accuracy which is acceptable to your application (default is exact floating-point match).
If this is a real failure, then check your compilation options and if the problem persists please report a bug."
<< endl;
return 1; }
return 0; }
3.4 INCREMENTAL MULTIFRACTAL &DWT
Spektrum multifractal adalah cara untuk meringkas statistik khusus tentang beberapa data, terkait dengan kelancaran dan keteraturan. Multifractals sekarang digunakan di banyak bidang fisika, biologi, keuangan, geologi. Algoritma ini menghitung "spektrum" sangat cepat. Hal ini juga dapat memperbaruinya ketika data baru menjadi tersedia. Sebuah algoritma disajikan untuk memperbarui spektrum multi-fraktal dari serangkaian waktu dalam waktu yang konstan ketika data baru tiba. The transformasi wavelet diskrit (DWT) dari seri waktu pertama diperbarui untuk nilai data baru. Hal ini dilakukan secara optimal dalam hal berbagi perhitungan sebelumnya, di O (L) waktu yang konstan, dengan L jumlah tingkat dekomposisi. Spektrum multi-fraktal ini kemudian diperbarui juga konstan-waktu. Teknik pra-perhitungan baru disajikan untuk lebih mempercepat proses ini. Semua kemungkinan keberpihakan data 2 L diperhitungkan dalam proses update inkremental. Estimasi spektrum yang dihasilkan lebih stabil, dibandingkan dengan metode DWT saat ini hanya menggunakan satu frame diad, sebagai tepat, dan lebih efisien. Hal ini disesuaikan untuk real-time on-line update dari seri wakt
3.4.1 Mengurus Data Lama
Sampai saat ini hanya data baru dianggap, tapi lebih tua nilai juga harus dihapus. Sayangnya, hal ini tidak mungkin untuk menghitung ulang masa lalu | F (λ) | nilai-nilai q, karena data yang sesuai itu justru dibuang siklik buffer. Untuk seri stasioner solusi akan membuat statistik dari titik pertama dari seri waktu dan mengabaikan masalah. Tanpa asumsi ini, titik-titik yang lebih tua harus dihapus. Solusinya adalah dengan menghitung 2λ pertama F (λ) nilai-nilai hanya sebelum memperbarui DWT dengan data baru, dan menghapus ini dari jumlah daya yang sesuai. Setelah keseluruhan siklus frame 2λ, paritas keselarasan sama mencapai lagi untuk buffer paritas di tingkat λ. kekuatan sum siap untuk diperbarui dengan data baru, tanpa poin tua.
Algoritma sekarang tampak seperti:
• Hitung 2λ nilai pertama | F (λ) | q untuk frame dan set terkait buffer paritas, untuk setiap λ tingkat. Hal ini dilakukan dengan data saat dan filter yang memadai sesuai dengan Persamaan 3.
• Siapkan jumlah kekuatan frame untuk masa depan pembaruan dengan menghapus nilai-nilai lama.
• Perbarui DWT yang bertahap seperti yang dijelaskan dalam Bagian 2. ini akan mengubah frame dan buffer paritas.
• Hitung 2λ nilai terakhir dari | F (λ) | q untuk baru frame. Memperbarui jumlah listrik dengan data baru. Pada akhir langkah ini, jumlah yang kekuatan Eq. 2 selalu memiliki sampai dengan nilai tanggal.Spektrum multi-fraktal dapat sekarang diturunkan. Komputasi Spektrum Seperti disebutkan sebelumnya, h (q) eksponen untuk multifractal analisis diperkirakan dari skala power-law dari f (λ, q) nilai. Untuk setiap skala s = 2λ, tujuannya adalah untuk menemukan h terbaik (q) yang sesuai:
dengan α yang berarti "sebanding dengan". . Persamaan 4 dapat ditulis:
dengan C1 independen konstan λ, dan C2 = QC1 + log2R menurut persamaan 2 dan 3, sehingga C2 juga tidak tergantung dari λ. Cara termudah melanjutkan terdiri dari setidaknya estimasi persegi untuk h (q) menggunakan L daya sum logaritma. Tapi untuk pas eksponensial ini akan memperkenalkan bias: skala yang lebih rendah akan diberikan kepentingan yang lebih tinggi dari skala yang lebih tinggi di estimasi. Weighted least square pas memungkinkan untuk mengembalikan pengaruh relatif dari masing-masing skala dengan memilih bobot yang memadai. Cara yang lebih baik untuk memperkirakan h (q) nilai-nilai demikian untuk meminimalkan:
Pembaca diundang untuk berkonsultasi misalnya, untuk derivasi dari solusi estimasi kuadrat terkecil tertimbang. Ketika menulis ulang solusi yang dengan parameter dari Pers. 6, h (q) diberikan dalam bentuk analisis berdasarkan:
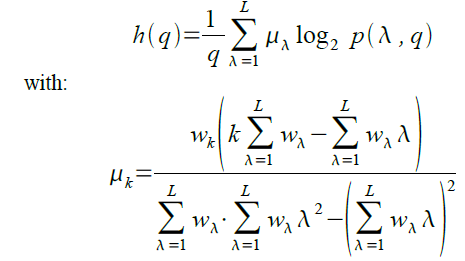
The unweighted pas kuadrat terkecil sesuai dengan semua bobot wλ yang sama. Solusi yang diberikan oleh Persamaan. 7 dan Eq. 8 telah ditulis ulang sedemikian rupa untuk menunjukkan dengan jelas istilah μλ: ini cara, μλ sengaja muncul sebagai berat badan dalam Pers. 7. menggunakan Eq. 8 adalah mungkin untuk pra-menghitung μλ / q untuk setiap q, λ. semua ada yang dapat dilakukan di real-time kemudian menambahkan tertimbang logaritma seperti pada Persamaan. 7, yang dapat dilakukan dengan sangat efficiently2. Pertanyaannya sekarang untuk menemukan bobot yang tepat sehingga semua skala diberikan pengaruh kira-kira sama. Hal ini dicapai dengan menggunakan hubungan eksponensial untuk bobot, idealnya sebanding dengan eksponensial fittest sendiri. Untuk pemasangan dari y = A ∙ 2BX, satu pilihan bisa menggunakan nilai-nilai y sebagai bobot: mereka seharusnya dekat dengan the fittest exponential3. Sayangnya, untuk perhitungan cepat dari h (q), sangat penting bahwa μλ tidak tergantung pada jumlah daya, jika pra-perhitungan mereka tidak akan mungkin. Apa yang diusulkan dalam algoritma ini adalah untuk memilih skala eksponensial yang sesuai dengan Brown klasik gerak: white noise terintegrasi, mono-fraktal dengan Hurst eksponen 0,5. Tanpa apriori pengetahuan tentang data (maka tanpa nilai-nilai y), tidak ada menebak dapat dibuat tentang ketergantungan jangka panjang dari data pada nilai sebelumnya. dengan H = 0,5, tidak ada asumsi yang dibuat pada kegigihan (H> 0,5) atau anti-ketekunan (H <0,5). Di satu sisi, hal ini tidak sebagus skema nilai-nilai y pembobotan tersebut. Di sisi lain, ini adalah eksponensial skala yang memberikan hasil lebih baik dibandingkan skema tertimbang tanpa biaya, karena memungkinkan pra-perhitungan. yang diusulkan bobot dengan demikian diberikan oleh:

Tergantung pada aplikasi pengguna, pilihan lain mungkin lebih memadai. Banyak fenomena alam pameran "merah muda noise ": power-law skala proporsional dengan inverse frekuensi. Terpadu pink noise memiliki Hurst eksponen dari 1,0. Sebuah pilihan wλ = 2λ mungkin lebih yang sesuai untuk acara-acara tersebut. Yang diusulkan publik implementasi tersedia algoritma ini default eq 9, tetapi menerima beban-pengguna didefinisikan sebagai parameter opsional. Kekuatan-sum update rutin disajikan sekarang termasuk langkah tambahan. Sebagai p (λ, q) nilai-nilai diperbarui, begitu juga h (q): logaritma ditimbang dari p (λ, q) ditambahkan untuk setiap tingkat. Ketika tingkat tertinggi tercapai, h baru (q) siap. Ini melengkapi algoritma multi-fraktal tambahan presentasi. DWT ini diperbarui untuk data baru, menggunakan kembali perhitungan sebelumnya dari frame diad yang sama. The jumlah daya yang diperbarui dengan cepat, berkat filter yang memungkinkan perhitungan langsung dari F (λ) dari data. Akhirnya, metode cepat diberikan untuk mendapatkan perkiraan h (q) dari jumlah listrik, dengan pra-menghitung faktor untuk eksponensial fit tertimbang.
3.4.2 Kesimpulan
Algoritma ini baru untuk memperbarui analisis multi-fraktal dalam waktu yang konstan memiliki kapasitas yang sama, presisi melekat, dan properti, sebagai metode yang didasarkan pada wavelet diskrit mengubah disajikan in Namun, jauh lebih efisien, bahkan dalam bentuk non-incremental nya, berkat pra-perhitungan bagian-bagian penting yang berbeda. incremental update menambah urutan lain besarnya kinerja. Opsional rata-rata seluruh frame diad 2L menyediakan stabilitas yang lebih dalam perkiraan untuk tingkat menengah dekomposisi. The DWT bagian tambahan dari algoritma ini dapat di sendiri memiliki aplikasi lain di samping estimasi spektrum multi-fraktal. Baik DWT dan multi-fraktal bagian sepenuhnya generik, mereka tidak membuat asumsi tentang data. Algoritma ini numerik stabil, tepat, dan efisien. Oleh karena itu berlaku untuk berbagai macam aplikasi yang memerlukan perhitungan real time.
Beberapa program yang disediakan:
• incremfa: Proses analisis lebih file data. Ketik "incremfa" tanpa parameter untuk bantuan. Program ini dijalankan melalui seluruh file data, tahap inisialisasi menggunakan analisis non-incremental, dan poin yang tersisa diproses secara bertahap.
• numericalStability: Kode untuk percobaan yang sesuai dalam artikel tersebut. 30 berjalan independen dari 10 juta update diproses untuk memantau titik perhitungan melayang mengambang antara non-incremental dan versi tambahan.
• PerformanceTest: Kode untuk percobaan yang sesuai dalam artikel tersebut. Konfigurasi yang berbeda diuji dengan jumlah tingkat, ukuran tingkat yang lebih tinggi. Waktu yang dibutuhkan untuk memproses update diukur untuk kedua versi tambahan dan non-incremental dari algoritma. Ada varian dalam waktu pembaruan karena multitasking OS. Langkah-langkah yang demikian membuat lebih banyak update.
• performanceTestReducedNq: Sama seperti di atas, tetapi dengan berbagai penurunan q: dari -5 sampai 5 bukannya -10 .. 10.
• precisionExperiment: Uji analisis presisi multifractal seri monofractal teoritis dengan nilai-nilai yang diketahui: H = 0,5 untuk gerak Brown, H = 1.0 untuk terintegrasi pink noise. Pengaruh banyak parameter yang diuji: jumlah tingkat, ukuran tingkat yang lebih tinggi, tetapi juga bingkai rata-rata, skema pembobotan, dll Rata-rata dan varians dari hasil lebih dari 30 berjalan independen dihitung.
• memVSCPUValidation: Cek perbedaan antara versi dari algoritma menggunakan lebih Memory (lebih cepat) atau lebih CPU (lambat). Karena CPU bekerja secara internal pada 80 bit sedangkan nilai ganda disimpan pada 64 bit, mungkin ada perbedaan kecil antara 2 algoritma versi. Anda dapat menggunakan ganda panjang, tapi kemudian pada beberapa sistem ini menimbulkan biaya yang outweights MEM vs keuntungan CPU. Perbedaannya hanya non-diabaikan untuk eksponen q negatif yang besar.
4.4.3 Souce Code Precision Experiment
/***************************************************************************
* Copyright (C) 2005 by Nicolas Brodu *
* nicolas.brodu@free.fr * *
* This program is free software; you can redistribute it and/or modify *
* it under the terms of the GNU General Public License as published by *
*the Free Software Foundation; either version 2 of the License, or *
* (at your option) any later version. * * *
* This program is distributed in the hope that it will be useful, *
* but WITHOUT ANY WARRANTY; without even the implied warranty of *
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the *
* GNU General Public License for more details. * * *
* You should have received a copy of the GNU General Public License *
* along with this program; if not, write to the *
* Free Software Foundation, Inc., *
* 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA. *
***************************************************************************/
#include <iostream>
#include <iomanip>
#include <fstream>
#include <sstream> using namespace std;
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include "Analyzer.h" #include "Utility.h"
int main(int argc, const char** argv) { Wavelet* wavelet = DW6::getInstance();
// Use correct weights for exponential fitting of integrated pink noise
// NOT using these weights would introduce a bias & loss of precision double weights[10];
for (int s=1; s<=10; ++s) { weights[s-1] = (double)(1 << s); }
// Also consider traditional unweighted least square double no_weights[10];
for (int s=1; s<=10; ++s) no_weights[s-1] = 1.0;
const int max_level = 10; const int max_nmin = 50; const int nmeasures = 3 * 3;
// number of level loops * number of nmin loops
#define INITIALIZER \ { \ {.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0},
\ {.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0}, \
{.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0}, \
{.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0}, \
{.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0}, \
{.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0}, \
{.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0}, \
{.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0}, \
{.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0,.0} \
}
// Stats double avg_iwn_disc[nmeasures][20] = INITIALIZER;
double dev_iwn_disc[nmeasures][20] = INITIALIZER; double avg_iwn_dev[nmeasures][20] = INITIALIZER;
double dev_iwn_dev[nmeasures][20] = INITIALIZER; double avg_iwn_keep[nmeasures][20] = INITIALIZER;
double dev_iwn_keep[nmeasures][20] = INITIALIZER; double avg_iwn_delta[nmeasures][20] = INITIALIZER;
double dev_iwn_delta[nmeasures][20] = INITIALIZER; double avg_ipn_disc[nmeasures][20] = INITIALIZER;
double dev_ipn_disc[nmeasures][20] = INITIALIZER; double avg_ipn_dev[nmeasures][20] = INITIALIZER;
double dev_ipn_dev[nmeasures][20] = INITIALIZER; double avg_ipn_keep[nmeasures][20] = INITIALIZER;
double dev_ipn_keep[nmeasures][20] = INITIALIZER; double avg_ipn_delta[nmeasures][20] = INITIALIZER;
double dev_ipn_delta[nmeasures][20] = INITIALIZER;
const int Nruns = 30; // Use low and high bits for the seed for (int run =0; run < Nruns; ++run) { Utility::RandomInit(1L<<run); int measureIdx = 0;
// To be fair, process all configurations on the same series in each run. // Integrated white noise double iwn_value = 0.0;
// Integrated pink noise double ipn_value = 0.0;
// Generate the series
// Ensure there is at least enough points at the max level int max_points = (1 << max_level)
* max_nmin + ((1 << max_level) -1)* (wavelet->support - 2) + (1 << max_level)*3;
// Forward rectangular integration of white noise is Brownian motion double *iwn = new double[max_points];
double *ipn = new double[max_points]; iwn[0] = 0.0; ipn[0] = 0.0; for (int i=1; i<max_points; ++i)
{ iwn[i] = iwn[i-1] + Utility::NRandom(); ipn[i] = ipn[i-1] + Utility::PRandom(); }
// number of levels of decomposition. for (int nlevel = 4; nlevel <= max_level; nlevel+=3) {
// pre-allocate filter for all loops using this level ScaleDeltaFilterArray* filters = ScaleDeltaFilterArray::getInstance(wavelet, 5);
// Number of data at the highest level for (int nmin = 10; nmin<=max_nmin; nmin += 20) {
// Create analyzers. // Process both "discard old points" and "keep old points" versions
// For "discard old points", process both "average over 2^L frames" // and "do not average" so as to get standard deviation.
// Analyzer for brownian motion (integrated white noise) // discard old points, no frame average Analyzer iwn_ana_disc_noavg(nlevel, nmin, wavelet, true, false);
// Analyzer for integrated pink noise // discard old points, no frame average
// Use correct weights Analyzer ipn_ana_disc_noavg(nlevel, nmin, wavelet, weights, true, false);
// frame averaging versions Analyzer iwn_ana_disc_avg(nlevel, nmin, wavelet, true, true); Analyzer ipn_ana_disc_avg(nlevel, nmin, wavelet, weights, true, true);
// Keep old points versions, frame average Analyzer iwn_ana_keep(nlevel, nmin, wavelet, false, true);
Analyzer ipn_ana_keep(nlevel, nmin, wavelet, weights, false, true);
// Keep old points versions, frame average, no weighting Analyzer iwn_ana_keep_no_weights(nlevel, nmin, wavelet, no_weights, false, true);
Analyzer ipn_ana_keep_no_weights(nlevel, nmin, wavelet, no_weights, false, true);
// Index of the first point that has a full history of frames for averaging int firstAvgFullHistory = iwn_ana_disc_avg.data.size() - 1 + (1<<nlevel);
double iwn_frame_to_frame_dev[20]; memset(iwn_frame_to_frame_dev, 0, 20*sizeof(double));
double ipn_frame_to_frame_dev[20];
memset(ipn_frame_to_frame_dev, 0, 20*sizeof(double));
// Process the given series with all analyzers for (int i=0; i<max_points; ++i)
{ iwn_ana_disc_noavg.newDataMFA(iwn[i]); ipn_ana_disc_noavg.newDataMFA(ipn[i]);
iwn_ana_disc_avg.newDataMFA(iwn[i]); ipn_ana_disc_avg.newDataMFA(ipn[i]);
iwn_ana_keep.newDataMFA(iwn[i]); ipn_ana_keep.newDataMFA(ipn[i]); iwn_ana_keep_no_weights.newDataMFA(iwn[i]);
ipn_ana_keep_no_weights.newDataMFA(ipn[i]);
// Compare between non-averaged and averaged version for each RESULT
// that is the latest hq value alone vs the latest 2^L average. if (i>=firstAvgFullHistory) { for (int j=0; j<20; ++j)
{ double delta = iwn_ana_disc_noavg.hq[j] - iwn_ana_disc_avg.hq[j];
iwn_frame_to_frame_dev[j] += delta * delta; delta = ipn_ana_disc_noavg.hq[j] - ipn_ana_disc_avg.hq[j];
ipn_frame_to_frame_dev[j] += delta * delta; } } }
// finish std dev computations for (int j=0; j<20; ++j)
{ iwn_frame_to_frame_dev[j] /= max_points - firstAvgFullHistory;
ipn_frame_to_frame_dev[j] /= max_points - firstAvgFullHistory; }
double m,v; cout << "Results for nlevel=" << nlevel << ", nmin=" << nmin << endl;
cout << "h(q)\tiwn_disc (dev) \tiwn_keep (delta_no_w) \tipn_disc (dev) \tipn_keep (delta_no_w)"<<endl;
cout.setf(ios_base::left); for (int i=0; i<20; ++i) { if (i>=10) cout << (9-i) << "\t"; else cout << (i+1) << "\t";
cout << setw(8) << iwn_ana_disc_avg.hq[i] << " ("<<setw(10) << iwn_frame_to_frame_dev[i] <<")\t";
cout << setw(8) << iwn_ana_keep.hq[i] << " (";
double delta_iwn = fabs(iwn_ana_keep.hq[i] - iwn_ana_keep_no_weights.hq[i]);
cout << setw(10) << delta_iwn << ") \t"; cout << setw(8) << ipn_ana_disc_avg.hq[i] << " ("<<setw(10) << ipn_frame_to_frame_dev[i]<< ")\t";
cout << setw(8) << ipn_ana_keep.hq[i] << " ("; double delta_ipn = fabs(ipn_ana_keep.hq[i] - ipn_ana_keep_no_weights.hq[i]);
cout << setw(10) << delta_ipn << ")"; cout << endl;
avg_iwn_disc[measureIdx][i] += iwn_ana_disc_avg.hq[i]; dev_iwn_disc[measureIdx][i] += iwn_ana_disc_avg.hq[i]
*iwn_ana_disc_avg.hq[i]; avg_iwn_dev[measureIdx][i] += iwn_frame_to_frame_dev[i];
dev_iwn_dev[measureIdx][i] += iwn_frame_to_frame_dev[i]
* iwn_frame_to_frame_dev[i]; avg_iwn_keep[measureIdx][i] += iwn_ana_keep.hq[i];
dev_iwn_keep[measureIdx][i] += iwn_ana_keep.hq[i]
* iwn_ana_keep.hq[i]; avg_iwn_delta[measureIdx][i] += delta_iwn; dev_iwn_delta[measureIdx][i] += delta_iwn * delta_iwn;
avg_ipn_disc[measureIdx][i] += ipn_ana_disc_avg.hq[i]; dev_ipn_disc[measureIdx][i] += ipn_ana_disc_avg.hq[i]
* ipn_ana_disc_avg.hq[i]; avg_ipn_dev[measureIdx][i] += ipn_frame_to_frame_dev[i];
dev_ipn_dev[measureIdx][i] += ipn_frame_to_frame_dev[i]
* ipn_frame_to_frame_dev[i]; avg_ipn_keep[measureIdx][i] += ipn_ana_keep.hq[i];
dev_ipn_keep[measureIdx][i] += ipn_ana_keep.hq[i]
* ipn_ana_keep.hq[i]; avg_ipn_delta[measureIdx][i] += delta_ipn; dev_ipn_delta[measureIdx][i] += delta_ipn * delta_ipn; }
++measureIdx; } // Once loops are done, we can dispose of this filter filters->unref(); } delete [] iwn; delete [] ipn; }
// Final stats int measureIdx = 0; for (int nlevel = 4; nlevel <= max_level; nlevel+=3) { for (int nmin = 10
; nmin<=max_nmin; nmin += 20) { for (int i=0; i<20; ++i) { avg_iwn_disc[measureIdx][i] /= Nruns;
dev_iwn_disc[measureIdx][i] = sqrt(dev_iwn_disc[measureIdx][i]/Nruns - avg_iwn_disc[measureIdx][i]
* avg_iwn_disc[measureIdx][i]); avg_iwn_dev[measureIdx][i] /= Nruns;
dev_iwn_dev[measureIdx][i] = sqrt(dev_iwn_dev[measureIdx][i]/Nruns - avg_iwn_dev[measureIdx][i]
* avg_iwn_dev[measureIdx][i]);
avg_iwn_keep[measureIdx][i] /= Nruns; dev_iwn_keep[measureIdx][i] = sqrt(dev_iwn_keep[measureIdx][i]/Nruns - avg_iwn_keep[measureIdx][i]
* avg_iwn_keep[measureIdx][i]); avg_iwn_delta[measureIdx][i] /= Nruns;
dev_iwn_delta[measureIdx][i] = sqrt(dev_iwn_delta[measureIdx][i]/Nruns - avg_iwn_delta[measureIdx][i] * avg_iwn_delta[measureIdx][i]);
avg_ipn_disc[measureIdx][i] /= Nruns; dev_ipn_disc[measureIdx][i] = sqrt(dev_ipn_disc[measureIdx][i]/Nruns - avg_ipn_disc[measureIdx][i]
* avg_ipn_disc[measureIdx][i]); avg_ipn_dev[measureIdx][i] /= Nruns;
dev_ipn_dev[measureIdx][i] = sqrt(dev_ipn_dev[measureIdx][i]/Nruns - avg_ipn_dev[measureIdx][i]
* avg_ipn_dev[measureIdx][i]); avg_ipn_keep[measureIdx][i] /= Nruns;
dev_ipn_keep[measureIdx][i] = sqrt(dev_ipn_keep[measureIdx][i]/Nruns - avg_ipn_keep[measureIdx][i]
* avg_ipn_keep[measureIdx][i]); avg_ipn_delta[measureIdx][i] /= Nruns;
dev_ipn_delta[measureIdx][i] = sqrt(dev_ipn_delta[measureIdx][i]/Nruns - avg_ipn_delta[measureIdx][i]
* avg_ipn_delta[measureIdx][i]); } cout << "Overall stats for nlevel=" << nlevel << ", nmin=" << nmin << ". Mean values." <<endl;
cout << "h(q)\tiwn_disc (dev) \tiwn_keep (delta_no_w) \tipn_disc (dev) \tipn_keep (delta_no_w)"<<endl;
for (int i=0; i<20; ++i) { if (i>=10) cout << (9-i) << "\t"; else cout << (i+1) << "\t";
cout << setw(8) << avg_iwn_disc[measureIdx][i] << " ("<<setw(10) << avg_iwn_dev[measureIdx][i] <<")\t";
cout << setw(8) << avg_iwn_keep[measureIdx][i] << " ("; cout << setw(10) << avg_iwn_delta[measureIdx][i] << ") \t";
cout << setw(8) << avg_ipn_disc[measureIdx][i] << " ("<<setw(10) << avg_ipn_dev[measureIdx][i] << ")\t";
cout << setw(8) << avg_ipn_keep[measureIdx][i] << " ("; cout << setw(10) << avg_ipn_delta[measureIdx][i] << ")";
cout << endl; } cout << "Overall stats for nlevel=" << nlevel << ", nmin=" << nmin << ". Standard deviations." <<endl;
cout << "h(q)\tiwn_disc (dev) \tiwn_keep (delta_no_w) \tipn_disc (dev) \tipn_keep (delta_no_w)"<<endl;
for (int i=0; i<20; ++i) { if (i>=10) cout << (9-i) << "\t"; else cout << (i+1) << "\t";
cout << setw(8) << dev_iwn_disc[measureIdx][i] << " ("<<setw(10) << dev_iwn_dev[measureIdx][i] <<")\t";
cout << setw(8) << dev_iwn_keep[measureIdx][i] << " ("; cout << setw(10) << dev_iwn_delta[measureIdx][i] << ") \t";
cout << setw(8) << dev_ipn_disc[measureIdx][i] << " ("<<setw(10) << dev_ipn_dev[measureIdx][i] << ")\t";
cout << setw(8) << dev_ipn_keep[measureIdx][i] << " ("; cout << setw(10) << dev_ipn_delta[measureIdx][i] << ")";
cout << endl;
} ++measureIdx;
}
}
}
3.5 Standalone reproducible float-ops
Sebuah komputer memiliki memori terbatas, dan tidak dapat mewakili infinity angka. Jika Anda menambahkan 0,1 + 0,1 di C + + Anda mungkin tidak akan mendapatkan hasil matematika 0,2. Masalahnya adalah bahwa apa yang Anda dapatkan tergantung pada banyak parameter. Di satu konfigurasi, Anda mungkin mendapatkan sesuatu seperti 0,1995, dan 0,1999 lain. Untuk sebagian besar dari program-program, perbedaan-perbedaan kecil tidak penting. Tetapi jika Anda ingin untuk mereproduksi hasil yang sama dua kali, untuk eksperimen ilmiah misalnya, pada mesin yang berbeda atau bahkan pada mesin yang sama tetapi dengan pilihan yang berbeda, maka Anda harus lebih berhati-hati. Lebih berhati-hati, karena perbedaan-perbedaan kecil kadang-kadang dapat mengumpulkan cukup cepat.
Mandiri direproduksi floating-point library yang merupakan subjek dari halaman ini memungkinkan Anda untuk mengontrol bagaimana perhitungan yang dilakukan dalam C + +. Tujuannya adalah untuk membuat program Anda memberikan hasil yang dapat diandalkan dan direproduksi.
Floating-point perhitungan sangat tergantung pada pelaksanaan FPU hardware, compiler dan optimasi, serta sistem matematika perpustakaan (libm). Percobaan biasanya direproduksi hanya pada mesin yang sama dengan perpustakaan sistem yang sama dan compiler yang sama dengan menggunakan opsi yang sama. Bahkan kemudian, C + + standar TIDAK menjamin hasil direproduksi. Contoh:
double x = 1,0; x / = 10,0;
ganda y = x; ... if (y == x)
{ / / INI TIDAK SELALU BENAR! }
Masalah terkait tetapi lebih umum adalah generasi nomor acak, sering diperlukan untuk percobaan reproducibility:
set_random_seed (42);
double x = random_number ();
Mungkin tidak mengembalikan x sama di berbagai FPUs / sistem / compiler / dll.
Masalah-masalah ini terkait dengan:
• Beberapa FPU (seperti x87 pada Linux) tetap secara default presisi intern (80 bit) lebih besar dari ukuran tipe dalam memori. Dalam contoh pertama, jika x adalah pada stack tapi y dalam register, perbandingan akan gagal. Lebih buruk lagi, apakah x dan / atau y adalah pada stack atau mendaftar tergantung pada apa yang Anda masukkan ke dalam ... bagian. Masalah ini dapat diatasi dengan membatasi presisi FPU internal untuk ukuran tipe dalam memori. Sayangnya, pada x87, beberapa operasi seperti fungsi transendental selalu dihitung pada 80 bit.
• Seberapa baik FPU Anda menerapkan standar IEEE754, dan khususnya, operasi bilangan denormal. Kode arithmetic_test yang disediakan reproducibly memberikan hasil yang berbeda antara SSE dan x87. Masalah ini TIDAK umumnya diselesaikan dengan membatasi presisi internal untuk ukuran tipe dalam memori. Mungkin ada hubungan bagaimanapun, khususnya pelampung denormal mungkin ganda normal, sehingga hal-hal presisi.
• Bagaimana compiler Anda berinteraksi dengan sistem perpustakaan matematika (libm) terutama dengan flag optimasi. Secara khusus, gcc-3.4 dan gcc-4.0 series dapat memberikan hasil yang berbeda pada sistem yang sama dengan library yang sama. Masalah ini sebagian diselesaikan dengan mengubah opsi compiler.
• Bahkan kemudian, standar IEEE754 memiliki beberapa celah mengenai jenis NaN. Secara khusus, ketika serialisasi hasil, file biner mungkin berbeda. Masalah ini dipecahkan dengan membandingkan arti logis dari NaN, dan tidak sedikit pola mereka.
Poin lebih untuk mempertimbangkan:
• SSE memiliki opsi untuk mempercepat perhitungan dengan mendekati Denormals dengan 0. Untuk beberapa aplikasi ini salah polos, tetapi untuk aplikasi lain seperti real-time DSP, Denormals adalah rasa sakit yang nyata dan ini hanya apa yang dibutuhkan (laporan telah dibuat bahwa denormal a kalikan dapat mengambil sebanyak 30 kali multiply normal). Karena default modus round-to-terdekat, Denormals cenderung tidak membatalkan ke 0 dan sebaliknya dapat terakumulasi. Menonaktifkan Denormals adalah built-in inti SSE FPU, tapi sayangnya itu tidak direproduksi pada x87. Dalam hal ini, hal itu mungkin untuk memeriksa kondisi denormal setelah setiap operasi (termasuk tugas) dan kemudian siram ke nol, berkat tipe wrapper. Catatan: Ini juga memecahkan masalah aforementionned dari denormal non-reproduksibilitas antara x87 dan SSE.
• Tidak ada ketergantungan eksternal. Semakin banyak dependensi, kemungkinan lebih dari versi mismatch. Perpustakaan ini harus mandiri, menyediakan fitur libm seluruh tanpa menggunakan sistem tertentu termasuk atau paket lainnya. Dengan cara ini, dapat dimasukkan dalam proyek seperti, dengan spesialisasi minimal (dan risiko kesalahan konfigurasi).
Dukungan untuk x87 (PC baru dan lebih tua) dan SSE (PC baru saja). Dukungan untuk implementasi software IEEE754.
• Dukungan untuk Simple, Double dan Extended jenis yang sesuai dengan jenis asli (float, double, long double), tapi itu tambahan mengurus presisi internal yang FPU dan penanganan denormal. Jenis ini mungkin alias sederhana atau C + + pembungkus, tergantung pada FPU dan konfigurasi.
• Full set fungsi libm. Bukan hanya subset, semua dari mereka, setidaknya untuk presisi Sederhana dan Double.
• Generasi nomor acak, menggunakan terbagus Mersenne Twister diciptakan oleh Takuji Nishimura dan Makoto Matsumoto.
• Mandiri (tanpa dependensi eksternal) dan mudah untuk memasukkan dalam sebuah proyek.
• Dukungan untuk menghapus Denormals, bahkan pada x87. Hal ini meningkatkan kinerja pada SSE, tetapi lambat di x87 (kecuali jika Anda menggunakan benar-benar banyak Denormals, dalam hal biaya wrapper mungkin kurang dari "tidak denormal" gain).
• Goodies: C99-fungsi seperti untuk pembulatan mode dan menjebak NaN, dan dukungan untuk implementasi software mengambang dengan libm. Ya, sekarang anda dapat menjalankan libm lebih softfloat, berkat C + + tipe wrapper
3.5.2 Kriteria Perbandingan
• Kinerja terbaik dicapai dengan "tidak denormal / SSE sederhana". Yang paling penting untuk kinerja adalah wrapper / asli, ukuran, maka Denormals atau tidak (kecuali menggunakan banyak Denormals, dalam hal ini "tidak ada Denormals" mungkin lebih penting daripada ukuran atau pembungkus).
• Presisi terbaik dicapai dengan "Denormals diperpanjang" mode. Yang paling penting untuk presisi adalah ukuran, maka denormal atau tidak.
• Kesesuaian Terbaik IEEE754 dicapai dengan "Soft" mode (dan hasil setara atas dengan SSE/x87). Kesesuaian dicapai hanya untuk Denormals.
4 BAB IV
4.1 STUDI KASUS
Pada tahun 1999 Game Developers Conference, Craig Reynolds memaparkan cara untuk model perilaku kemudi untuk otonom characters. Dengan menggunakan model titik-massa untuk agen dan dinamika Newton, gerakan agen sepenuhnya ditentukan oleh kekuatan-kekuatan itu diterapkan melalui waktu.
Kekuatan ini terbagi dalam dua kategori:
- kekuatan lingkungan eksternal. Gaya berat yang segera datang ke pikiran pengaruh dari luar, tetapi bukan satu-satunya dalam kategori ini. Agen biasanya pasif terhadap kekuatan-kekuatan gaya berat, dan mereka diterapkan apa pun keputusan agen.
Keputusan - agen internal itu, berdasarkan kemampuannya. Dalam permainan balap mobil misalnya, agen dibatasi oleh kecepatan maksimum dan dan percepatan. Dalam batas-batas ini, agen bebas untuk memutuskan di mana memaksa untuk menerapkan untuk mencapai tujuannya. Demikian pula, semua pemain dapat lakukan untuk bertindak atas agen adalah memilih yang memaksa untuk menerapkan pada saat (meskipun melalui antarmuka user friendly, tetapi hasil akhir adalah sama sejauh simulasi yang bersangkutan).
Akibatnya, tujuan dari AI adalah untuk menghasilkan kekuatan-kekuatan ini sedemikian rupa untuk bersaing dengan pemain. Skema 1 adalah ilustrasi ini: The AI agen memiliki tujuan untuk mencapai target yang diberikan. Mengingat arah depan saat ini, kekuatan dari lingkungan dan keterbatasan, AI memilih kekuatan steering untuk menerapkan. Hal ini memberikan arah depan baru, dan secara implisit mendefinisikan lintasan.
Gambar 4.1 Steering kekuatan untuk berlaku untuk mencapai target
Definisi pasukan kemudi untuk diterapkan ke beberapa situasi yang terdefinisi dengan baik diberikan in1. Misalnya, mengarahkan untuk menghindari dari target mobile, mengarahkan untuk mencari titik tetap, mengarahkan untuk menjelajahi lingkungan dengan cara acak tetapi konsisten,
Kami dapat mempertimbangkan ini sebagai blok bangunan untuk AI, dan peran AI kemudian menjadi memilih dan menggabungkan perilaku steering yang tepat sesuai dengan tujuan yang dimaksudkan.
Ini adalah motivasi yang awalnya dipandu proyek, dan yang pada gilirannya mengarah pada pengembangan lingkungan yang lengkap. Memang, untuk AI untuk mengerjakan sesuatu, pertama-tama kita perlu mendefinisikan dunia, fisika, serta skenario. Sebuah studi kasus yang sudah tersedia untuk perilaku kemudi dalam bentuk library2 OpenSteer, dikembangkan sebagai ilustrasi konkrit dari kertas tersebut. Salah satu tujuan dari proyek ini adalah demikian untuk memperpanjang gagasan yang disajikan di sana, dan menyediakan lingkungan yang kaya di mana tantangan yang menarik dapat dikembangkan untuk AI.
Negara maju dalam proyek ini adalah lingkungan 3D penuh. Untuk membuat ini agen yang relevan aspek 3D yang diizinkan untuk terbang, dan medan bukanlah pesawat tak terbatas datar melainkan bidang tinggi yang dihasilkan sepenuhnya, dengan rintangan. Dunia ini baik terbuka di segala arah, atau dibuat siklik di kedua X dan Y (cyclicity di Z tidak relevan dalam hal ini karena kami menggunakan medan a). Yang sederhana seperti ini mungkin terdengar, ia memiliki dampak teknis banyak dan tidak langsung, termasuk pada permintaan lingkungan, generasi medan, dan deteksi tabrakan dan penghindaran. Di sisi lain, jika dunia siklik cukup besar, hal ini efektif untuk menekan kondisi batas, atau risiko bahwa agen membubarkan hingga tak terbatas. Berikut bagian detil titik-titik ini, dan berhubungan apa kesulitan yang dihadapi dalam menerapkan mereka untuk proyek ini.
4.1.2 Lokalitas dan lingkungan query
Masalah dalam menemukan tetangga adalah bahwa algoritma naif berjalan melalui semua agen lain dan membandingkan jarak mereka secara inheren O (n), yang menjadi O (n2) seperti yang telah kita menerapkannya pada semua agen setiap langkah. Ini adalah keterbatasan yang kuat untuk skalabilitas, dan mengingat fakta kita juga harus memesan beberapa daya komputasi untuk AI itu sendiri, metode lain yang diperlukan.
OpenSteer2 menggunakan "SuperBrick" implementasi. Ini terdiri dalam membelah dunia bersama setiap dimensi ke dalam sebuah array regular dari batu bata. Kemudian masing-masing blok menyimpan daftar semua agen
terletak di wilayahnya. Ketika agen melakukan permintaan lokalitas, dengan cepat dapat menghilangkan semua blok lebih jauh dari jarak permintaan maksimum, dan menjalankan melalui daftar blok yang tersisa. Ini adalah kasus klasik memori vs konsumsi sumber daya pengolahan, sebagai kotak halus sesuai dengan eliminasi yang lebih tepat dari jauh blok. Dalam kasus apapun, ketika semua agen cukup tersebar di seluruh dunia dan mereka query jarak hanya cukup singkat, algoritma ini memberikan peningkatan yang substansial atas O (n2) yang awal. Algoritma ini dengan demikian digunakan kembali dalam proyek ini. Itu harus dimodifikasi untuk memperhitungkan dunia wrap, meskipun. Hal ini tidak sulit, tetapi tidak sepele baik, dan saya membuatnya begitu bahwa fungsi permintaan baru siklik mengintegrasikan dengan kode asli dengan cara yang sepenuhnya kompatibel. Algoritma lain dapat digunakan, yang akan kita sebut Neighborhood Propagasi dalam kerangka proyek ini. Meskipun algoritma ini diciptakan secara independen untuk proyek ini, itu begitu sederhana referensi sebelumnya untuk itu dapat dengan mudah ditemukan. Misalnya di Lalat, dan Mega Lalat software oleh Keith Wiley3. Ini terdiri dalam setiap agen mempertahankan daftar tetangganya pada waktu tertentu. Kemudian, ketika seorang agen bergerak, itu update daftar ini secara lokal dengan memeriksa pada tetangga sebelumnya, tetangga mereka sendiri juga, sampai tingkat rekursi maksimal. Biasanya pencarian orde kedua sederhana digunakan, karena kalau biaya rekursi ini akan outweight manfaat alam lokal. Salah satu asumsi dalam algoritma ini adalah bahwa agen tidak bergerak terlalu cepat, sehingga kemungkinan agen tetangga masih di sekitarnya, atau setidaknya di sekitar tetangga lama. Sayangnya, asumsi ini memiliki kelemahan serius, dan agen bergerak cepat tidak terdeteksi. Juga, jika agen akan terisolasi dari kelompok, tidak pernah dapat ditemukan kembali. Sebuah cara untuk mengatasi keterbatasan kedua ini akan men-tweak algoritma untuk mempertahankan referensi terakhir, bahkan jika itu terlalu jauh. Tetapi bahkan ini tidak akan mengatasi masalah mendasar dengan algoritma ini: dua kelompok bisa menyeberang tanpa pernah melihat satu sama lain (lihat skema 2).
-------------------------------------------------------------------------------------------------------------------------------
Algoritma propagasi lingkungan terdiri dalam menjaga daftar tetangga lokal. Ini secara implisit mendefinisikan metrik: tingkat rekursi yang diperlukan untuk mencari agen lain. Tapi itu tidak termasuk cara untuk mendeteksi tetangga baru berdasarkan jarak riil mereka. Akibatnya, dua agen yang tampaknya jauh sesuai dengan algoritma metrik mungkin sebenarnya sangat dekat di kejauhan, dan benar-benar kehilangan satu sama lain .
Gambar 4.2 Masalah Fundamental propagasi lingkungan
Untuk mengatasi keterbatasan ini, saya menerapkan modus campuran untuk proyek ini. Para agen menggunakan propagasi lingkungan dengan cepat memperbarui daftar lokal mereka, dan melengkapi ini dengan permintaan lokalitas dalam database batu bata (sebelum propagasi untuk efisiensi). Caranya adalah dengan hanya mencakup sebagian kecil dari agen dalam database, sehingga daftar yang lebih pendek dalam batu bata, dan sehingga bahkan dalam kasus ini agen semua terletak di beberapa batu bata (atau jika jarak permintaan terlalu besar ) algoritma tidak menurunkan ke O (n2) kasus. Dengan penambahan ini, harapan adalah bahwa setidaknya satu agen dalam dua kelompok pertemuan akan terlokalisasi dalam database, dan termasuk dalam setidaknya satu dari yang lain anggota kelompok tetangga. Setelah beberapa update, seluruh kelompok menjadi dikenal satu sama lain. Mode campuran ini menggabungkan yang terbaik dari kedua algoritma, tanpa terlalu banyak overhead. Selain itu, kehandalan tergantung hanya pada satu parameter: probabilitas agen untuk dimasukkan dalam database. Dengan mengadaptasi parameter ini dengan situasi, itu mungkin untuk perdagangan tetangga keandalan deteksi untuk kecepatan, dengan cara yang terkontrol. Proyek ini saat ini tidak memperbarui probabilitas ini pada saat run-time. Perpanjangan menarik akan merancang sebuah algoritma yang melakukan ini secara otomatis dengan heuristik pintar, untuk memungkinkan peningkatan kecepatan dalam kasus situasi cukup konsisten dengan hanya propagasi tetangga.
Akhirnya, perlu dicatat bahwa hambatan di medan dapat membantu juga. Dengan membuat hambatan (atau lebih umum item pemandangan) berpartisipasi dalam propagasi tetangga, keandalan algoritma ini sangat meningkat, terutama jika hambatan (lebih umum pembantu) yang tersebar merata di seluruh daerah. Selain itu, dengan termasuk hambatan dalam database batu bata dalam modus campuran, adalah mungkin untuk memastikan tabrakan agen-hambatan akan selalu terdeteksi.
Seperti disebutkan sebelumnya, cyclicity dunia bukanlah masalah besar pada tingkat konseptual, tetapi pelaksanaannya meresap dalam arti memiliki konsekuensi pada banyak bagian lain dari proyek. Tak satu pun dari konsekuensi itu sendiri masalah besar, dan hampir semua mudah untuk melaksanakan, tapi itu hanya cyclicity yang memiliki efek yang jauh lebih daripada yang saya pikir sebelumnya. Saya sudah sebutkan efeknya query lokalitas. Contoh lain: ketika sedang mudah untuk membungkus posisi, dan dengan sedikit lebih peduli posisi perbedaan vektor dan jarak antara dua agen, membungkus ini harus dimasukkan pada semua tingkatan dalam rutinitas AI dan pasukan kemudi bukan perhitungan biasa.
Ini bahkan lebih buruk bagi agen ke agen tabrakan, vektor kemudi penghindaran: setidaknya satu ray harus dilemparkan ke arah menuju titik masa depan diperkirakan jarak minimum sepanjang dua lintasan agen, dengan agen target diterjemahkan ke titik ini untuk persimpangan ray. Lempar membungkus siklik dalam hal ini, dan itu kasus yang lebih khusus untuk menangani. Cyclicity juga memiliki efek generasi medan: algoritma harus mengambil dalam account dan menghasilkan peta tileable untuk bidang tinggi. Normals harus dirata-ratakan kedua belah pihak, dan dunia ruang vertex array harus mencakup satu baris tambahan dalam setiap dimensi sehingga medan yang dihasilkan dapat ditempatkan sisi menjadi sisi dengan dirinya sendiri (tanpa pengulangan ini, segitiga bergabung dengan poin terakhir dan pertama akan hilang).
4.1.4 Generasi Medan
Teknik generasi medan saya gunakan untuk proyek ini terinspirasi dari Perlin Noise. Idenya adalah untuk menghasilkan suara pada frekuensi spasial yang berbeda, dan menerapkan filter interpolasi untuk menggabungkan tingkat yang berbeda pada skala yang sama. Alih-alih menggunakan (bi / tri) teknik linear filtering, atau teknik spline berbasis klasik, saya telah digunakan untuk proyek ini rekonstruksi wavelet. Memang, wavelet secara tegas dirancang untuk analisis frekuensi multi-skala, sehingga tampaknya pilihan alami untuk mengganti filter interpolasi dengan filter wavelet. Saya telah memilih wavelet Daubechies W6 untuk tugas ini. Hal ini sangat sederhana untuk menerapkan, dan memiliki sifat fraktal, yang awalnya saya pikir akan properti yang bagus untuk medan a. Tapi apakah ini merupakan keuntungan atau tidak diberi smoothing saya akan berbicara tentang bawah, terbuka untuk diskusi. Saya kira yang lain "alami" pilihan akan dari Coiflet & spline keluarga, atau Daubechies bi-ortogonal (9,7) wavelet yang digunakan dalam standar JPEG 2000. Karena tidak satupun dari transformasi wavelet adalah sebagai sederhana untuk menerapkan sebagai filter W6, dan karena potensi keuntungan (atau kekurangan) dalam menggunakan mereka jelas untuk proyek ini, menempel W6 tampaknya pilihan yang wajar.
Gambar 4.3 Kebutuhan filter smoothing
Bagaimana filter smoothing? Masalah yang umum saat interpolasi pada kedua dimensi gambar secara mandiri penampakan artefak kuning persegi. W6 tidak dibebaskan dari cacat ini, meskipun dalam hal ini artefak berbentuk garis dan echos spasial persegi (lihat Skema). Ini mungkin terlihat lucu untuk yang digunakan untuk metode interpolasi lain, tetapi tetap tidak diinginkan. Sebuah cara untuk mengatasi hal ini adalah untuk kelancaran (atau blur) koefisien sebelum setiap interpolasi skala, sehingga pada akhirnya blok persegi telah menyebar sampai batas tertentu, lebih-lebih untuk frekuensi yang lebih rendah. Dalam proyek ini, konvolusi filter yang standar digunakan. Koefisien dan efek ditunjukkan dalam Skema: Kita bisa melihat artefak telah menghilang dari peta ketinggian kedua. Sekarang datang masalah memilih distribusi frekuensi. Memang, jika suara di semua frekuensi yang ditambahkan dengan berat yang sama, hasilnya akan terlihat sangat banyak seperti white noise dan akan terlalu teratur untuk medan yang realistis. Dengan demikian, skala masing-masing frekuensi spasial dengan rasio yang signifikan diperlukan. Tapi bagaimana cara memilih rasio ini? Untuk proyek ini, saya telah menggunakan gagasan Kegigihan, awalnya diperkenalkan oleh Benoit Mandelbrot. Singkatnya, itu sesuai dengan peluruhan eksponensial dari nilai rasio skala sehubungan dengan frekuensi. Hal ini dapat dilihat sebagai ukuran seberapa halus hasil akhir akan (Lihat Skema 4). Seperti yang sering, kualitas model dapat diukur dengan betapa sedikit (bukan berapa banyak!) Parameter yang diperlukan untuk tune-kan. Dalam hal ini, model Ketekunan adalah salah satu yang sangat baik seperti yang memungkinkan untuk menghasilkan distribusi untuk sejumlah tingkat frekuensi (sehingga setiap resolusi medan) dengan hanya satu parameter yang sama! Hal ini juga sangat baik disesuaikan dengan analisis fraktal, dan melengkapi koefisien skala yang digunakan untuk menyimpan energi dalam rekonstruksi wavelet, jadi memang pilihan yang cocok untuk proyek ini.
Gambar 4.4 Pengaruh parameter ketekunan
Akhirnya, trik terakhir adalah untuk meningkatkan perbedaan tinggi, sehingga menghasilkan dataran besar dan pegunungan tajam daripada bukit seragam. Hal ini dapat hanya dilakukan dengan skala semua parameter antara 0 dan 1, dan mengambil eksponensial dari nilai-nilai dengan eksponen yang dipilih. Ini adalah parameter kedua model medan saya, dan efeknya disajikan dalam Skema 5. Sekarang bahwa kita memiliki lapangan tinggi yang cocok, dapat ditingkatkan sepanjang 3 dimensi untuk mengakomodasi ukuran dunia diberikan. Mari kita menerapkan model warna untuk itu. Untuk membuatnya sederhana, saya menggunakan warna rumput untuk bagian bawah, warna batu untuk bagian atas, dan warna bumi untuk lereng. Setiap vertex menerima warna sesuai dengan tingginya,
Gambar 4.5 Efek dari parameter eksponen
dan cosinus dari medan yang normal pada saat ini dengan horizontal. Sebuah interpolasi linier pertama dilakukan antara bagian bawah dan warna atas, maka kedua antara nilai ini dan warna lereng menggunakan produk tersebut dot. Akhirnya, simpul yang menyatu dalam segitiga dengan memisahkan setiap ketinggian bidang quad sepanjang lebih tinggi diagonal. Salah satu hasil yang mungkin ditunjukkan dalam skema 6. ----------------------------------------------------------------------------------------------------------------------------
Dalam screen shot ini, kita dapat melihat dataran yang sempurna tileable. Untuk mencapai cyclicity ini, perawatan harus diambil di setiap tahapan konstruksi: interpolasi wavelet, smoothing filter, dan rata-rata normal.
Gambar 4.6 Contoh medan, dengan 2 siklus.
4.1.5 Simulasi & fisika
Sekarang bahwa kita memiliki dunia, kita juga perlu aturan untuk mendefinisikan bagaimana agen dapat bertindak di atasnya. OpenSteer menggunakan model titik-massa, dan terbatas Fisika Newton. Dalam proyek ini, kami akan memperpanjang agak, tapi dengan masalah kinerja di pikiran: Fisika harus diterapkan apapun AI, pada frekuensi tinggi (lihat Simulator Bagian nanti), dan karena itu harus bisa lebih cepat mungkin. Tujuannya di sini bukan untuk memberikan tingkat industri simulasi fisik: kita perlu realistis mencari aplikasi, tidak setia representasi realitas. Beberapa efek seperti propagasi gelombang, atau materi sifat, yang termasuk dalam beberapa permainan tetapi tidak dipertimbangkan di sini: Sementara menyediakan nilai tambah bagi realisme, ini memiliki sedikit jika tidak berdampak pada AI dan karena itu mereka rasio biaya / manfaat dianggap terlalu tinggi untuk ini proyek.
Di sisi lain, saya memperpanjang pointmass sederhana model dengan fitur berikut: Konsumsi energi. Hal ini menentukan kemampuan agen untuk menerapkan beberapa kekuatan kemudi. ini adalah sangat penting dalam skenario mangsa / predator misalnya: ketika burung tidak memiliki lebih banyak energi yang jatuh dengan gravitasi. Untuk game balapan ketika mobil tidak memiliki lebih banyak bahan bakar berhenti. Di sisi lain, Proyek ini membuat energi asumsi adalah selalu perlu untuk menerapkan gaya kemudi. ini mungkin tidak benar misalnya dalam kasus mobil yang masih bisa berubah dengan kecepatan yang tersisa bahkan ketika tidak ada bahan bakar tetap. Efek ini jelas memiliki dampak pada AI, tetapi juga biasanya hanya transien. Jadi itu diperkirakan tidak akan kerugian besar untuk proyek ini.
Selain itu, rotasi momentum hack (lihat di bawah) memiliki efek samping membuat langkah minimal masih mungkin bersama arah depan. Sebuah perpanjangan masa depan ini proyek bisa untuk menghilangkan efek samping ini dan memperkenalkan gagasan otonomi minimal Sebuah koefisien drag untuk memperlambat benda bergerak. Bagian ini masih perlu perbaikan lebih lanjut seperti untuk sekarang tidak mengambil di account perbedaan antara udara dan lantai. Efek ini adalah diperkenalkan terutama untuk memperlambat benda bergerak tanpa energi, dan membuat negara ini lebih transien. Seperti dikatakan, menerapkan gesekan yang Model perlambatan untuk lantai tentu akan perpanjangan yang menarik untuk proyek ini.
Penyimpanan energi. Ini diperkenalkan untuk model Bahkan beberapa massa yang diperlukan untuk menyimpan energi dalam beberapa kasus. Sebagai contoh, mobil yang menggunakan bahan bakar memiliki kapasitas penyimpanan yang terbatas, dan bahan bakar itu sendiri meningkatkan massa mobil. Sebuah predator hanya bisa makan begitu banyak, dan juga memiliki peningkatan massa. pada Sebaliknya, mobil surya memiliki energi tak terbatas kapasitas dan tidak perlu bahan bakar toko. Dalam proyek ini, batas energi dan konversi mass storage rasio diperhitungkan. Kecepatan maksimum dan panjang gaya steering. ini sudah hadir di perpustakaan OpenSteer, dan mewakili keterbatasan fisik suatu agen. Gravity. Sebagai koefisien hambatan di atas, hal ini tidak benar-benar bagian dari model agen melainkan dari lingkungan. Efeknya yang paling nyata untuk agen terbang. Efek samping yang menarik dari gravitasi adalah untuk memungkinkan agen untuk mencapai kecepatan lebih tinggi dari batasan maksimum sendiri, yang dapat sangat menarik bagi burung predator AI. Sebuah hack momentum rotasi. Sebuah trik yang digunakan untuk momentum rotasi Model, tidak secara fisik berbasis. Ini memiliki dampak kecil pada AI (lihat ucapan di "konsumsi energi" di atas), tetapi memiliki biaya run-time yang sangat rendah, dan meningkatkan realisme oleh membuat agen berat mengaktifkan lebih lambat pada sendiri.
4.1.6 Koreksi Sikap
Dengan mempertimbangkan semua efek yang disajikan di atas, sekarang mungkin untuk menghitung efek dari kekuatan kemudi diterapkan pada agen. Akibatnya, agen akan memiliki posisi baru, dan maju ke arah yang baru. Untuk proyek ini, saya kembali menggunakan gagasan tentang angka empat Sikap, banyak digunakan dalam industry4 spacial. Hal ini memungkinkan untuk sepenuhnya menentukan lokal untuk dunia-ruang transformasi, dengan hanya beberapa parameter: posisi, pusat rotasi, sikap, dan skala. Untuk proyek ini, pusat rotasi (dalam ruang lokal) dan skala diperhitungkan, tetapi tetap dalam praktek. Kami sekarang hanya memiliki dua parameter untuk khawatir tentang: posisi dan sikap.
Posisi mudah untuk memperbarui. Ini hanya masalah mengubah kekuatan untuk percepatan, mengintegrasikannya ke dalam kecepatan, kemudian mempercepat ke perbedaan posisi, dan menambahkan posisi lama. Sikap, di sisi lain, merupakan arah dari ruang vektor maju lokal dalam ruang dunia, bersama-sama dengan jumlah rotasi ruang lokal memiliki sekitar vektor ke depan ini. Vektor depan baru diberikan oleh integrasi sebelumnya. Masalahnya berasal dari fakta tak terhingga banyaknya rotasi dapat memetakan vektor maju yang lama ke yang baru, dan kita harus memilih hanya satu.
Salah satu kemungkinan adalah untuk memilih rotasi sudut untuk memetakan vektor maju lama ke vektor maju baru. Hal ini dapat dilakukan dengan mengubah angka empat menggunakan sifat geometris hanya cepat, dan tidak ada panggilan mahal untuk fungsi trigonometri atau pendekatan tabel tepat mereka. Karena kita harus menerapkan transformasi pada setiap update integrasi, ini adalah properti yang sangat diinginkan
.
Ini terdiri dalam mempertahankan vektor Up di samping vektor ke depan, dan menambahkan rotasi kedua sekitar vektor maju baru. Rotasi kedua ini tidak mengubah arah depan, dan membawa Up vektor baru dalam bidang didefinisikan oleh baru ke depan dan target Up vektor. Dengan menetapkan sasaran Up vektor ini ke lantai normal, efek yang dicapai adalah untuk agen untuk selalu sesuai dengan lantai horizontal lokal. Oleh karena itu mereka lancar mengikuti kelengkungan lantai ketika mereka bergerak.
Perawatan juga diambil untuk rekondisi angka empat setelah terlalu banyak rotasi, ketika hal ini menjadi perlu. Ini adalah masalah umum yang muncul dengan matriks, dimana setelah banyak perkalian matriks kesalahan numerik menumpuk: Rotasi akhir tidak sesuai dengan salah satu yang diinginkan dan objek skala bawah.
Quaternions sedikit kurang sensitif dibandingkan matriks karena mereka menggunakan lebih sedikit perkalian untuk rotasi, tetapi tentu masih tunduk pada roundups kesalahan numerik. Dan meskipun kurang sering, kesalahan lebih terlihat: obyek cenderung geser dan meratakan. Dengan demikian, dalam proyek ini, saya mendeteksi ketika angka empat yang terlalu buruk AC, dan itu renormalized. Jika tambahan transformasi dari depan ruang lokal tidak sesuai dengan ruang dunia maju dengan presisi yang cukup baik, angka empat sepenuhnya dibangun kembali dan bukan hanya renormalized.
Dengan demikian, para agen selalu memiliki orientasi yang benar tidak peduli berapa lama simulasi berjalan, dan itu masih mungkin untuk menggunakan cepat pembaruan angka empat tambahan untuk menghitung sikap baru
Sebuah simulator mungkin bukan hal yang termudah untuk melaksanakan, tetapi merupakan alat yang sangat berguna setelah Anda memilikinya. Dalam konteks proyek ini, dengan simulator Aku benar-benar berarti versi dasar: scheduler untuk mengatur acara, dan fasilitas waktu logis.
Beberapa keuntungan utama menyediakan adalah:
- Kemampuan untuk memisahkan frekuensi AI, integrasi fisika, dan tugas-tugas administrasi. Memang, AI tidak kebutuhan tidak dapat diterapkan sesering integrasi fisika, dan mengumpulkan sampah misalnya dapat dipanggil bahkan kurang sering.
- Kemampuan untuk menyebarkan kejadian dalam waktu sehingga untuk penggunaan terbaik sumber daya CPU, dan untuk memungkinkan degradasi anggun di frame rate konstan ketika sistem kelebihan beban (lihat Skema 8).
- Kemampuan untuk menjalankan program pada skala waktu yang berbeda. Ini mungkin untuk berhenti dan restart simulasi, memperlambatnya dan menganalisis apa yang terjadi, atau bahkan untuk menjalankannya lebih cepat dari real-time untuk mempelajari efek jangka panjang jika konsumsi CPU memungkinkan. Dengan ekstensi, ketika simulator dijeda, mungkin untuk cerita bersambung objek untuk penyimpanan permanen dan "menyelamatkan" seluruh simulasi (tidak diimplementasikan dalam proyek ini, tapi layak catatan).
- Manfaat dari pemesanan sepenuhnya deterministik peristiwa, yang terutama berguna dalam pemrograman muti-benang. Bersama dengan benih acak eksplisit, ini memberikan kontribusi untuk membuat eksperimen ilmiah direproduksi.
Bingkai menjatuhkan berlaku ketika menunggu refresh vertikal berikutnya pembagi rate. Dalam contoh ini, tingkat vertikal 60Hz mengarah ke 30 dan 20 frame per detik. Jika perhitungan tidak dapat disimpan dalam satu frame, maka panjang frame meningkat ke yang berikutnya pembagi. Tidak hanya dapat hasil ini dalam penurunan drastis dalam bingkai rate, tapi CPU masih terbuang.
panjang siklus terpisah. Jika semua agen dapat menyelesaikan mereka fisika dalam satu frame, hasil visual yang masih akan halus. Jika tidak, hanya agen yang tidak bisa menyelesaikan fisika mereka tidak akan pindah selama frame ini. Ini adalah kasus degradasi anggun, dan bahkan mungkin kentara jika jumlah agen melewatkan frame rendah cukup. Selain itu, agen-agen ini memiliki prioritas pada orang lain untuk melakukan fisika mereka pada frame berikutnya, sehingga degradasi adalah statistik diencerkan atas semua agen dalam waktu. AI dan tugas-tugas administratif tidak perlu diterapkan sesering fisika, dan memiliki sedikit jika ada efek visual, sehingga dapat mentolerir Nasib lebih buruk. Akhirnya, ada CPU yang terbuang menunggu di frame berikutnya, asalkan benang grafis dan simulator memiliki didefinisikan dengan baik bagian yang dilindungi.
Selain itu, adalah mungkin untuk jatuh kembali ke pertama kasus Skema 8 jika diinginkan. Mengapa akan ini berguna, ketika menyebarkan peristiwa disajikan sebagai keuntungan? Dalam hal jumlah agen adalah sangat tinggi, dan ketika integrasi fisika Langkah ini sangat sederhana, biaya pengiriman dan penanganan peristiwa di simulator dapat menjadi dari urutan biaya untuk memproses peristiwa sendiri. Dalam hal ini, mungkin lebih baik untuk berkumpul kembali fisika banyak agen hanya dalam beberapa peristiwa. Kasus ekstrim hanya satu event untuk seluruh fisika setara dengan yang pertama diagram dalam Skema 8. Hal yang sama juga berlaku untuk AI, tetapi kasus tersebut hanya berarti dalam sangat situasi khusus. Biasanya, itu jauh lebih baik untuk menambahkan beberapa jitter ketika posting setiap event sehingga mereka tersebar di seluruh siklus, dan manfaat dari efek degradasi progresif harus itu terjadi.
4.1.8 Menghindari Tabrakan dan Deteksi
Menghindari tabrakan dan deteksi 2 tugas terpisah. Penghindaran adalah masalah menemukan kekuatan kemudi untuk mencegah tabrakan, dan deteksi adalah masalah menentukan apakah dua agen menduduki ruang yang sama atau tidak. The menghindari tabrakan rutin dari proyek ini adalah awalnya didasarkan pada ide-ide perpustakaan OpenSteer, tetapi menggunakan persimpangan OpenSceneGraph rutinitas bukan bounding bola. setelah beberapaeksperimentasi, masih belum jelas apakah manfaat persimpangan geometri nyata bernilai biaya tambahan mereka atas ray / sphere persimpangan. Tes yang lebih maju bisa menjadi perpanjangan untuk proyek ini, terutama pada perilaku jelas agen dalam setiap kasus, dan untuk membuat statistik pada jumlah tabrakan dihindari atau not.Whatever metode persimpangan yang dipilih, menghindari tabrakan memanfaatkan lingkungan query untuk mulai dengan. Sekarang bahwa saya telah disajikan simulator, yang layak disebut tabrakan yang kebutuhan penghindaran hanya dapat diterapkan pada frekuensi AI,
untuk menghasilkan kekuatan kemudi. karena lokalitas query biasanya utama CPU konsumen dengan Sejauh ini, ini adalah peningkatan yang sangat besar dibandingkan dengan simulasi berbasis frame-rate! Tabrakan adalah di sisi lain diperlukan pada setiap langkah integrasi. Untungnya, tidak ada permintaan lingkungan baru diperlukan: Dengan asumsi frekuensi AI sudah cukup untuk menangkap perubahan lingkungan memungkinkan untuk hanya menggunakan daftar saat tetangga untuk jarak perbandingan. Tentu saja, jika agen berasal dari jauh dalam waktu kurang dari satu siklus AI tidak akan terdeteksi. Dalam mode campuran, beberapa siklus AI mungkin bahkan diperlukan dalam kasus yang lebih buruk di mana tidak ada agen dalam database lokalitas, dan mereka membutuhkan beberapa update untuk menemukan satu sama lain.Namun, berkat kecepatan maksimum keterbatasan dan dengan selalu termasuk setidaknya hambatan dalam database lokalitas, tabrakan deteksi cukup handal dan sangat cepat dalam hal ini proyek. Apa yang harus dilakukan ketika dua agen bertabrakan adalah hal lain masalah, dan tergantung pada skenario.
Skenario
Empat aplikasi yang dikembangkan dalam proyek ini. Mereka disajikan di bawah dalam urutan kompleksitas.
Kawanan
Aplikasi dasar ini terutama menguji algoritma lokalitas, tetapi juga rutin integrasi fisik, koreksi sikap sudut terpendek, tabrakan, dan AI sangat dasar.Aplikasi dasar ini terutama tes lokalitas algoritma, tetapi juga integrasi fisik rutin, koreksi sikap sudut terpendek, tabrakan, dan AI sangat dasar.
Semua agen termasuk dalam dunia non-siklik, tanpa medan. Untuk menghindari agen dari meninggalkan pemandangan sama sekali, agen terisolasi mengembara sekitar secara acak dengan bias dikonfigurasi arah asal. Tampilan visual Final swarm sangat tergantung pada nilai bias ini: yang lebih besar itu, dan lebih kompak adalah swarm.
https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgJezzcSpt946jsWzzZO1OZe-OhyphenhyphenaPU18E3bOLJ_KPgrQOgOkvC9wi19TMdUiOzj-81nZoi_t-c5WlnQ4pyx71CDJOyJOnq4dC6B4hJFm3bTLecIVZ_FIzHJJAgkLNCjBiR3n_C5WJMfTgk/s1600/13.PNG" alt="figure sosfkill/gambar/13.png" style="max-width: 311px; max-height: 223px;"/>
Gambar 4.10 Contoh segerombolan 1000 agen
Ketika di hadapan orang lain, agen mengadopsi perilaku boid seperti: The AI menggabungkan kemudi kekuatan untuk menghindari tetangga, bergerak di lokal rata-rata kelompok ke depan arah, dan bergerak menuju pusat kelompok lokal. hanya terlihat agen diperhitungkan. Ini memiliki sisi efek membuat pemimpin kelompok mengikuti mengembara / perilaku Bias. Tergantung pada apakah agen lain mengambil memimpin atau tidak, kelompok biasanya tidak berjalan terlalu jauh sebelum datang kembali ke rumah. Deteksi Tabrakan dilakukan dalam integrasi langkah, tapi secara opsional dapat dimatikan. ketika tabrakan terdeteksi, agen bangkit kembali. untuk menambahkan realisme, juga menyimpan beberapa komponen maju ke arah sebelumnya, dan agen bertabrakan depan juga. Hasilnya adalah awan agen yang bergerak dalam kelompok pola, dengan kadang-kadang jejak agen antara kelompok-kelompok. Struktur 3D-nya penuh hanya dapat ditangkap dengan menjalankan program, Gambar 4.10 menunjukkan seluruh awan dari jarak tertentu. sekarang mengingatkan formasi nyamuk alami.
4.1.9 Colliterra
Ini singkatan dari tabrakan dan medan. ini Program meluas swarm dengan membuat dunia siklik, dengan medan, dan dengan rintangan. itu cyclicity memungkinkan untuk menghapus bias ke arah asal, dan dengan demikian kita tidak lagi memiliki awan atau global yang pembentukan kelompok.
Gambar 4.11 Contoh program Colliterra
Sebuah contoh dari program colliterra. Di latar depan pojok bawah kiri kita dapat melihat contoh kritis buruk menghindari tabrakan saat mendarat. Hal ini mungkin disebabkan oleh Bahkan agen cyan bergerak terlalu cepat karena pengaruh gravitasi, dan dideteksi hambatan terlambat untuk menghindarinya dengan keterbatasan kekuatan kemudi. Tabrakan berada di sisi lain ditangani dengan benar (agen bangkit kembali di simulasi re-start). Kita lihat juga melihat bahwa kuning-hijau dan agen merah magenta (pada gambar sudut yang sama) mengikuti kelengkungan lantai setempat. Di latar belakang, kita bisa melihat kelompok yang sama dan pola jejak seperti pada contoh swarm.
AI menggunakan kembali gagasan mengembara acak ketika terisolasi, dan boid-seperti perilaku sebaliknya. Kendala penghindaran juga diperhitungkan dan akan didahulukan dari boid seperti perilaku. Selain itu, semua agen memiliki probabilitas kecil untuk benar-benar mengabaikan AI ini dan lepas landas. mereka kemudian terus melonjak sampai "aman" ketinggian tertentu dimana mereka melanjutkan perilaku boid seperti dalam 3D penuh. Hal ini memungkinkan untuk menguji pengaruh gravitasi, yang dapat diubah pada saat run-time. Termasuk efek kecepatan lebih cepat dari sendiri-maksimum, yang muncul ketika agen jatuh kembali ke tanah. Semua agen memiliki pasokan energi yang tak terbatas, dan akan mengejar AI ini tanpa batas. Berjalan panjang memiliki menunjukkan perilaku agen stabil dan ini Rezim tercapai dalam beberapa detik setelah start simulasi. Seperti disebutkan sebelumnya, agennya memelihara vektor mereka Up selaras di lantai normal. itu Hasilnya terlihat di Schema 10, di mana agen selalu menjaga horisontal lokal ruang mereka benar. Efek pada terbang agen terlihat dalam Skema 11: vektor up disimpan di lantai normal dan maju pesawat vektor.
Gambar 4.12 Agen lepas landas dalam program colliterra
Contoh lain dari program colliterra mana agen memutuskan untuk lepas landas dan agen lainnya mengikuti langkah tersebut.
Predator memperluas AI di colliterra untuk memperkenalkan gagasan energi. Agen sekarang mengkonsumsi energi ketika mereka menerapkan kekuatan kemudi, dan satunya cara memperbaharuiitu adalah dengan "makan" yang lain agen. Oleh karena itu nama predator pertandingan: the agen di salah satu specie dapat mendahului pada semua spesies lain. Tentu saja, bila tidak ada energi tetap, agen tidak memiliki pilihan tetapi untuk menjadi mangsa pasif. AI sekarang dibagi dalam dua bagian: Bagian pertama adalah sama seperti dalam program colliterra ketika tetangga hanya teman-teman (atau dalam terisolasi kasus agent). Di sisi lain, ketika agen lain spesies terdeteksi, reaksi adalah sebagai berikut: Jika mendekati mangsa dari belakang, itu mengejar dalam harapan tidak terlihat. Jika sebaliknya yang agen saling berhadapan, mereka mencoba untuk menghindari terlibat dalam pertandingan kematian. Hal ini tercermin dalam rutinitas penanganan tabrakan: Ketika dua agen bertabrakan, pemenangnya adalah ditentukan sebagai berikut. - Jika salah satu agen menangkap lain dari belakang, itu tanpa syarat menang. Ingat agen hanya "Melihat" apa yang ada di depan mereka, sehingga kasus ini melihat predator datang.
- Jika agen saling berhadapan (depan mereka vektor dot product negatif) maka kematian pertandingan yang terlibat. Agen dengan lebih energi memenangkan pertandingan, tetapi kehilangan jumlah energi sama dengan apa agen lain memiliki. Model ini situasi di mana mangsa bereaksi dengan segala kekuatan yang tersisa, serta predator harus berjuang. Jika hasil imbang terjadi, kedua agen mati. Pemenang pertandingan itu "makan" mangsanya dengan mengkonversi massa mangsa menjadi energi sesuai dengan rasio jejak energi, dan maksimum kapasitas energi. Skor spesies dipantau bersama-sama dengan pemenang tersisa energi.
Gambar 4.13 Agen mengejar satu sama lain dalam predator pertandingan
Pada pertandingan predator kita masih melihat kelompok dan trails pola, tetapi biasanya specie yang mendominasi dalam setiap kelompok. ini Tampaknya logis diberi kesempatan sedikit agen harus bertahan ketika dikelilingi oleh kelompok bermusuhan. Di sisi lain, AI terbatas diterapkan dalam program ini tidak mengarah pada munculnya perilaku kelompok mangsa, seperti yang kita lihat di alam, ketika memangsa berkumpul untuk menjadi lebih kuat dan berbagi informasi. Bagaimana program ini berkembang dalam jangka panjang tergantung pada kondisi awal. ketika Rasio jejak energi terlalu tinggi atau energi membatasi terlalu rendah, para agen tidak bisa menyimpan cukup energi dan habis sebelum mereka mampu menangkap mangsa. Kemudian, kami memiliki koleksi bots pasif perlahan-lahan bergerak di depan mereka arah. Masalah ini muncul ketika populasi turun ke bawah ambang batas, di mana pertemuan kesempatan terlalu terbatas. ini threshold juga mencerminkan fakta tidak maju perilaku predator diperkenalkan di AI, tapi itu sangat tergantung pada parameter energi dalam setiap kasus. Di sisi lain, ketika agen dapat mengumpulkan dan mempertahankan energi cukup, "kesempatan pertemuan tidak cukup "ambang batas populasi sangat rendah.
Dalam hal ini, para agen memiliki lebih banyak waktu untuk berkeliaran di sekitar sebelum mereka kehabisan energi. Kami juga melihat agen lebih mampu untuk terbang, yang mereka jarang bisa dilakukan di kasus sebelumnya. catatan bahwa AI tidak berubah, hanya saja agen mengambil terbang dalam kasus pertama yang segera kehabisan energi dan dibawa kembali ke lantai dengan cara yang keras ... Kerangka Proyek ini menawarkan banyak ekstensi dan kemungkinan untuk menguji berbagai AI. memperluas dan menciptakan rutinitas AI baru mungkin dengan demikian dipertimbangkan di masa depan. A khususnya ekstensi menarik diadili dengan saraf jaringan, dengan harapan mendapatkan awal yang baik titik untuk algoritma genetika lebih lanjut. ini adalah rinci pada bagian berikutnya
4.2 Crogai
Akronim ini singkatan Crowds, GA, AI, dan mencerminkan niat awal ini. Masalah utama dengan algoritma genetika dalam konteks proyek ini, akan menemukan yang baik titik awal. Memang, agen diambil dengan random kondisi awal memiliki sedikit jika ada kesempatan sama sekali untuk mendahului dan bertahan cukup lama untuk bereproduksi. Dengan demikian, langkah pertama adalah untuk menyediakan mereka dengan AI yang baik untuk memulai dengan, dan langkah kedua akan
akan berkembang AI ini. Sebuah pilihan kandidat untuk mesin-belajar AI adalah jaringan saraf. Dan dalam jaringan saraf, a sangat terbatas tetapi model sederhana adalah dua-layer perceptron. Model ini juga cukup cepat, yang adalah properti yang diinginkan jika ingin diterapkan masing-masing Langkah AI untuk populasi agen. Masalah utama sekarang adalah untuk merancang saraf ini jaringan sedemikian rupa untuk dapat diterapkan pada ini AI. Dengan kata lain, jumlah ini menemukan baik iinputs, output untuk steeriing fforce mappiing, dan a ffunctiion kesalahan yang baik. Sebuah cara untuk memperhitungkan variiablle nomor off neiighbors juga harus ditemukan. Arsitektur ditahan disajikan dalam Skema 13. Setelah jaringan dibangun dan siap dilatih untuk meminimalkan fungsi kesalahan, kebutuhan guru. Setiap eksplisit AI ditulis dalam kerangka proyek ini dapat digunakan sebagai guru, misalnya satu di game predator. itu jaringan maka akan mencoba untuk mempelajari apa yang guru ini AI tidak.
Untuk setiap agen tetangga, jaringan dijalankan dengan masukan berikut. Parameter ditandai ’c’ adalah umum untuk semua tetangga perhitungan, tetapi diberikan tetap pada per-tetangga basis.Parameters ditandai ’n’ tergantung tetangga-, dan diatur untuk masing-masing 0,0,0, -2 bila tidak ada tetangga. Parameter ditandai ’e’ hanya akan digunakan selama fase evolusi, dan bukan tahap pelatihan. Mereka mewakili work in progress, belum termasuk dalam proyek. Mereka dimaksudkan untuk mewakili pengetahuan yang diperoleh dari bagian agent, dan reset ketika membuat baru keturunan.
- c: sejumlah hambatan
- c: jumlah teman
- c: jumlah musuh
- c: ketinggian
- c: sisa energi
- c: taking massa dalam penyimpanan energi akun
- n: jarak kuadrat untuk menargetkan
- n: arah target yang relatif ke depan kami
arah. Apakah target di samping?
- n: Target arah depan relatif ini agen arah depan: Apakah kita di depan atau balik target?
- n: specie dari target. -2 Adalah bendera untuk menunjukkan ada tetangga bukan specie sebuah, -1 dicadangkan untuk benda yang tidak diketahui, 0 untuk rintangan.
Gambar 4.14 Arsitektur Jaringan Neural
Jaringan ini diterapkan untuk masing-masing tetangga m dengan sesuai masukan n. Ini menghasilkan output m, yang faktor untuk m sesuai pasukan kemudi per-agent. Untuk setiap angkatan, hasil agen dikumpulkan sesuai pada kebijakan yang dipilih: dirata-ratakan, atau norma yang lebih besar mengambil semua. ini memberikan f vektor unik untuk setiap angkatan steering. f ini vektor kemudian sekali lagi dikumpulkan dengan kebijakan kedua pilihan, menjadi kekuatan F final. Gaya ini adalah hasil akhir AI.
Fitur yang direncanakan untuk algoritma genetika adalah:
- en: pesan dari target kepada dunia.
- ec: pesan saat ini agen ini kepada dunia.
- ec: memori (pesan pribadi agen ini itu sendiri) dari pembaruan AI sebelumnya, indeks 0. - ec: ...
- ec: memori dari sebelumnya AI update, indeks jumlah memori – 1
Setiap keluaran jaringan adalah koefisien untuk diterapkan ke vektor. Vektor tersebut diberikan di bawah ini, dan spidol ’n’ dan ’c’ memiliki arti yang sama seperti untuk masukan. Selain itu, nilai-nilai skalar yang rencananya akan diproduksi selama fase evolusi, tetapi tidak termasuk dalam proyek belum. Mereka ditandai ’e’ dan dimaksudkan untuk digunakan hanya setelah pelatihan (mereka bukan bagian dari fungsi error).
- n: mencari posisi target - n: lari posisi target
- n: menghindari tabrakan dengan sasaran - n: mengejar target
- n: menghindari sasaran
- n: posisi perbedaan vektor - n: target ke depan arah
- c: arah mengembara (dibatasi arah acak, lihat Agent.h)
- c: lantai yang normal pada saat ini
- c: maju arah sebelumnya kita sendiri Fitur yang direncanakan untuk algoritma genetika adalah:
- ec: pesan baru agen ini ke seluruh dunia
- ec: memori baru (pesan pribadi agen ini untuk dirinya sendiri) untuk pembaruan AI berikutnya, indeks 0 - ec: ...
- ec: memori baru update AI berikutnya, nomor indeks memori - 1 Jaringan saraf dijalankan untuk setiap tetangga, maka perhitungan dikumpulkan sesuai dengan kebijakan berikut (lihat Skema 13). Untuk setiap vektor hasil:
- rata-rata: vektor rata-rata dari semua kontribusi perhitungan tetangga untuk mendapatkan vektor kemudi. A koefisien semua 1 / m.
- Pemenang mengambil semua: Dapatkan norma keluaran terbesar * vektor gaya sebagai satu-satunya kekuatan untuk kemudi ini. A koefisien semua nol, kecuali persis p koefisien yang 1: orang-orang untuk terbesar hasil keluaran norma. Setelah kekuatan steering dihitung untuk setiap output, pasukan kemudian sekali lagi dikumpulkan sesuai dengan salah satu kebijakan berikut untuk kekuatan kemudi akhir:
- rata-rata: kontribusi rata-rata dari semua hasil kemudi individu. Setiap koefisien b adalah 1 / p. Pemenang - mengambil semua: mempertahankan hanya terbesar kekuatan norma individu steering. Semua koefisien b adalah nol, kecuali satu untuk hasil terbesar norma kemudi yang 1.
Averaging harus pada prinsipnya memberikan hasil yang lebih halus dan memungkinkan pelatihan semua bobot jaringan.
Pemenang mengambil semua seharusnya memberikan lebih alami hasil (ex: menghindari terdekat), dan mungkin bagaimana guru AI memutuskan hanya satu tindakan yang jelas dalam kasus di mana beberapa pilihan bisa dibuat. Sayangnya seperti gradien adalah 0 untuk beban yang tidak terpakai dalam kasus ini, fase pelatihan mungkin tidak pergi begitu baik.
Tentu saja, kedua kebijakan dapat dicampur. Aku mencoba semua kombinasi untuk proyek ini, tetapi hasilnya tidak sangat baik sejauh ini (lihat di bawah). fungsi transfer
Dua-lapisan jaringan saraf juga membutuhkan fungsi transfer, biasanya sigmoid seperti. Saya merancang satu terutama untuk proyek ini:
f (x) = x / (1 + abs (x))
Fungsi ini sigmoid seperti, -1 / +1 dibatasi, terus-menerus untuk urutan apapun, dan jauh lebih cepat untuk menghitung dari tanh. Hal ini juga sayangnya lambat untuk berkumpul, lihat catatan di bawah ini.
Banyak paket jaringan saraf menggunakan tanh, ke titik itu telah menjadi fungsi standar untuk digunakan. Ini memiliki properti yang sangat bagus memiliki tanh ’= 1 - tanh2. Dengan demikian, backpropagation dapat dibuat lebih cepat dengan menggunakan kembali perhitungan sebelumnya untuk derivatif, dan sangat sering tujuannya adalah untuk melatih terbaik jaringan sehingga ini adalah properti yang sangat diinginkan. Lainnya menggunakan fungsi sigmoid s (x) = 1 / (1 + exp (-x)), dimana s ’= s. (1-s), untuk alasan yang sama.
Namun, dalam tujuan jangka panjang dari proyek ini, jaringan saraf dimaksudkan untuk digunakan terutama dalam mode maju, dan backpropagation / pelatihan eksplisit hanya cara untuk menyediakan titik awal yang cukup baik untuk algoritma genetika untuk bekerja pada.
Dengan demikian, titik paling penting adalah memiliki fungsi transfer tercepat: kita akan menerapkannya banyak, jumlah unit tersembunyi ditambah beberapa kali output per agen, dan bagi banyak agen! Di sisi lain, hal itu tidak terlalu menjadi masalah jika kita tidak bisa kembali menggunakan beberapa perhitungan di backpropagation: fase belajar dilakukan hanya sekali, dan cukup cepat karena dengan fungsi di atas pula.
Sebagai soal fakta, dengan fungsi di atas, kita dapat menggunakan kembali hasil dengan cara yang sama seperti untuk tanh: f ’(x) = 1 / (1 + abs (x)) ^ 2, sehingga: f ’= (1 - abs (f)) ^ 2. Jadi, bahkan fase pelatihan cepat.
Catatan: Untuk moderat temuan ini, eksperimen numerik menunjukkan bahwa fungsi ini jauh lebih lambat untuk berkumpul saat pelatihan dari tanh, tentang urutan apa sigmoid tidak. Jadi, jika semua yang Anda inginkan adalah konvergensi cepat, tanh adalah pilihan yang baik. Di sisi lain, karena kita tidak memerlukan konvergensi persis seperti semua yang kita inginkan di sini adalah titik awal yang baik untuk algoritma genetika, kami tidak peduli banyak. Juga, banyak orang menggunakan sigmoid, dan fungsi ini adalah tentang kecepatan konvergensi yang sama, sehingga benar-benar masalah selera saya kira.
4.2.3 Fungsi Kesalahan
Selama fase pelatihan, fungsi kesalahan dihitung sebagai berikut:
E = 1 - | F * T | /2 *1 | * F-T |
Dimana F adalah gaya hasil yang diperoleh dari jaringan dengan metode yang telah dijelaskan sebelumnya, dan di mana T adalah kekuatan sasaran untuk belajar dari guru AI (ini adalah apa yang guru lakukan untuk dirinya sendiri dalam situasi ini).
Saya merancang fungsi kesalahan ini terutama untuk proyek ini: termasuk di dalamnya baik arah dan komponen normatif. Selain itu, hal ini membuat lanskap kesalahan halus di sekitar masing-masing minimum. Jadi, saya punya harapan yang masuk akal untuk konvergensi menggunakan fungsi ini.
Sejak fase pelatihan ini adalah stateless, tanpa memori, jaringan saraf dapat didaftarkan pada banyak guru pada saat yang sama untuk mendapatkan data dari berbagai situasi yang berbeda. Hal ini memungkinkan untuk mengumpulkan data yang sangat efisien: 200 guru berjalan pada frekuensi AI dari 5 kali per detik akan menghasilkan 1000 pemetaan per detik, dan angka-angka itu tidak berlebihan mengingat hardware saat ini. Pelatihan ini adalah on-line gradien yang sangat sederhana keturunan. Batch mode digunakan untuk menyebarkan error gradient kembali ke masing-masing tetangga perhitungan jaringan individu. Ini berarti gradien error rata-rata pada semua tetangga, sejak backpropagation sebenarnya bekerja pada jaringan yang sama diulang m kali. Perpanjangan untuk proyek ini akan mencoba cara lain untuk menghitung turunan penyimpangan terhadap setiap parameter jaringan.
4.2.4 Analisis Kegagalan
Hasilnya cukup mengecewakan. jaringan tidak bertemu sama sekali, tidak peduli yang mentransfer Fungsi ini digunakan, dan tidak peduli yang penyederhanaan ini dilakukan untuk fungsi error. Saya menduga alasan utama adalah:
- Jaringan yang sama juga digunakan ketika ada di ada tetangga. Tapi dalam kasus ini, banyak parameter tidak ada artinya, dan guru AI tidak menggunakan tindakan yang sama sekali berbeda. ini titik harus diperbaiki dalam versi masa depan proyek.
- Mungkin pemetaan terlalu terputus-putus. Multi-layer yang perceptrons approximators fungsi seharusnya universal, tapi ini adalah asumsi lapisan tersembunyi tak terbatas ukuran. Dalam prakteknya, ketika fungsi untuk perkiraan terlalu terputus-putus, jaringan gagal untuk menemukan pendekatan yang baik. saya memiliki telah menemui masalah ini sangat sedikit tahun yang lalu, dalam konteks lain, jadi saya tahu yang Efek tidak dapat diabaikan. Sebuah kata akhir Aku punya banyak menyenangkan pemrograman proyek ini, dan saya juga belajar banyak. Saya berharap ini akan terus hidup seperti yang saya mendistribusikannya di Internet, dan bahwa orang-orang akan menikmatinya sebanyak yang saya lakukan.
5 BAB V
PENUTUP
Crowd behaviour merupakan pendekatan untuk memahami aspek individualistis atau perilaku setiap agen atau personal. Sebuah pendekatan yang menggabungkan kedua aspek dan mampu beradaptasi tergantung pada situasi, akan lebih menggambarkan perilaku alami manusia. Crogai merupakan penerapan Artificial Intelegence ke dalam Crowd Behaviour, menjadikannya percobaan untuk memperkenalkan beberapa kecerdasan buatan dalam skenario dimana terdapat kerumunan besar dari karakter-karakter dan kerumunan ini menjalankan suatu perilaku tertentu sehingga memungkinkan untuk merancang simulasi dan percobaan perbedaan kecerdasan buatan ke dalam lingkungan 3D yang lengkap seperti engine fisik skala kecil, terrain, dan collision handling.
Tujuan utamanya adalah untuk membentuk lingkungan environmental yang lebih baik, yang dapat memperbolehkan kecerdasan buatan untuk berperan aktif. Adapun kelebihan daripada Crogai di antaranya: Cross-multi platform (bisa di Linux dan Windows), tidak memiliki spesifikasi khusus untuk hardwarenya, sehingga menjalankan aplikasi ini lebih ringan.
Demikianlah materi yang dapat kami sampaikan mengenai Artificial Intelligence and Crowd Behaviour. Tentunya kami sebagai tim penulis dan penyusun menyadari segala kekurangan yang terdapat pada buku ini.Namun, kami sangat berharap buku ini bisa bermanfaat bagi siapapun yang membacanya. Kami selalu terbuka terhadap kritik pedas dan saran yang membangun dari pembaca sekalian, karena kami menganggap semua itu merupakan modal utama untuk terus melangkah maju dan tak pernah berhenti untuk mempelajari hal baru.
Bibliography
[1] Wikipedia, “Kecerdasan Buatan”, http://id.wikipedia.org/wiki/Kecerdasan\_{}buatan
[2] Anonim, “AI”, http://wsilfi.staff.gunadarma.ac.id/Downloads/files/4338/1-AI.pdf
[3] Anonim, “Metode Pencarian Heuristik”, http://www.slideshare.net/ceezabramovic/metode-pencarian-heuristik
[4] Anonim, “AI”, http://herriyance.trigunadharma.ac.id/wp-content/uploads/2012/06/Bab4\_{}AI.pdf
[5] Anonim, “Artificial Inteligence”, http://mayamusthopaif13.wordpress.com/2013/12/18/artificial-intelligence/
[6] Anonim, “Crowd Simulation”, http://www.crowdsimulationgroup.co.uk/
[7] Wikipedia, “Crowd Simulation”, http://en.wikipedia.org/wiki/Crowd\_{}simulation
[8] Wikipedia, “Morph Target Animation”, http://en.wikipedia.org/wiki/Morph\_{}target\_{}animation
[9] Anonim, “Crogai”, http://nicolas.brodu.net/en/programmation/crogai/index.html
[10] Anonim, “Crowd Simulation Submission”, http://www.cs.gsu.edu/xhu/papers/crowdSimulation\_{}submission.pdf
[11] Anonim, “Pengertian Simulasi”, http://seaparamita.blogspot.com/2009/08/pengertian-simulasi\_{}29.html
[12] Wikipedia, “Vektor”, http://en.wikipedia.org/wiki/Vector\_{}field
[13] Wikipedia, “Skalar”, http://en.wikipedia.org/wiki/Scalar\_{}field
[14] Anonim, “Query Sphere Indexing”, http://nicolas.brodu.net/common/recherche/publications/QuerySphereIndexing.pdf
[15] Anonim, “Streflop”, http://nicolas.brodu.net/common/programmation/streflop/streflop-0.3.tar.gz
[16] Anonim “Incremental Algorithm”, http://nicolas.brodu.net/common/programmation/incremfa/incrementalMFA-1.2.tar.gz
[17] Anonim, “Pengertian C++”, http://comput-techno.blogspot.com/2013/01/pengertian-dari-c-beserta-fungsi.html
[18] Anonim, “Sejarah C++”, http://tugas-arini.blogspot.com/
[19] Anonim, “Struktur Bahasa C”, http://dhanhost.com/struktur-bahasa-c/
[20] Anonim, “Crogai Report”, http://nicolas.brodu.net/common/programmation/crogai/CrogaiReport.pdf